 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Sustainability Intention of ESG Fund Disclosure using Few-Shot Learning
Jul 09, 2024



Global sustainable fund universe encompasses open-end funds and exchange-traded funds (ETF) that, by prospectus or other regulatory filings, claim to focus on Environment, Social and Governance (ESG). Challengingly, the claims can only be confirmed by examining the textual disclosures to check if there is presence of intentionality and ESG focus on its investment strategy. Currently, there is no regulation to enforce sustainability in ESG products space. This paper proposes a unique method and system to classify and score the fund prospectuses in the sustainable universe regarding specificity and transparency of language. We aim to employ few-shot learners to identify specific, ambiguous, and generic sustainable investment-related language. Additionally, we construct a ratio metric to determine language score and rating to rank products and quantify sustainability claims for US sustainable universe. As a by-product, we publish manually annotated quality training dataset on Hugging Face (ESG-Prospectus-Clarity-Category under cc-by-nc-sa-4.0) of more than 1K ESG textual statements. The performance of the few-shot finetuning approach is compared with zero-shot models e.g., Llama-13B, GPT 3.5 Turbo etc. We found that prompting large language models are not accurate for domain specific tasks due to misalignment issues. The few-shot finetuning techniques outperform zero-shot models by large margins of more than absolute ~30% in precision, recall and F1 metrics on completely unseen ESG languages (test set). Overall, the paper attempts to establish a systematic and scalable approach to measure and rate sustainability intention quantitatively for sustainable funds using texts in prospectus. Regulatory bodies, investors, and advisors may utilize the findings of this research to reduce cognitive load in investigating or screening of ESG funds which accurately reflects the ESG intention.
Comparative Study of Language Models on Cross-Domain Data with Model Agnostic Explainability
Sep 09, 2020
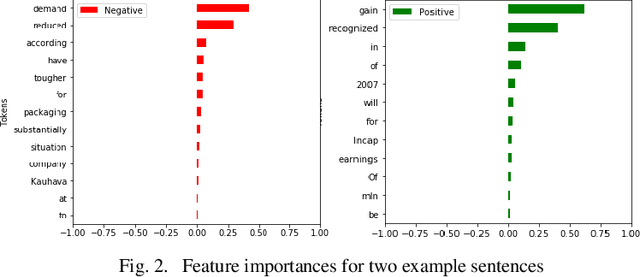
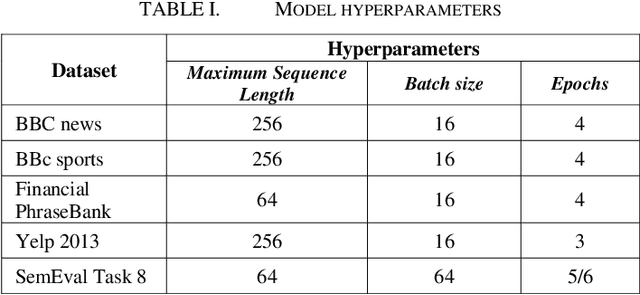

With the recent influx of bidirectional contextualized transformer language models in the NLP, it becomes a necessity to have a systematic comparative study of these models on variety of datasets. Also, the performance of these language models has not been explored on non-GLUE datasets. The study presented in paper compares the state-of-the-art language models - BERT, ELECTRA and its derivatives which include RoBERTa, ALBERT and DistilBERT. We conducted experiments by finetuning these models for cross domain and disparate data and penned an in-depth analysis of model's performances. Moreover, an explainability of language models coherent with pretraining is presented which verifies the context capturing capabilities of these models through a model agnostic approach. The experimental results establish new state-of-the-art for Yelp 2013 rating classification task and Financial Phrasebank sentiment detection task with 69% accuracy and 88.2% accuracy respectively. Finally, the study conferred here can greatly assist industry researchers in choosing the language model effectively in terms of performance or compute efficiency.