 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Language Models on Cross-Domain Data with Model Agnostic Explainability
Sep 09, 2020
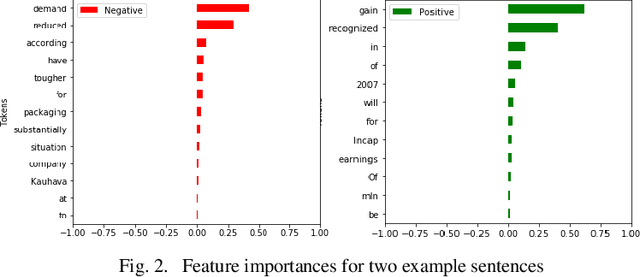
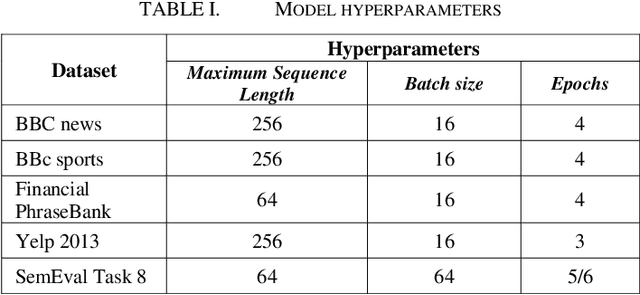

With the recent influx of bidirectional contextualized transformer language models in the NLP, it becomes a necessity to have a systematic comparative study of these models on variety of datasets. Also, the performance of these language models has not been explored on non-GLUE datasets. The study presented in paper compares the state-of-the-art language models - BERT, ELECTRA and its derivatives which include RoBERTa, ALBERT and DistilBERT. We conducted experiments by finetuning these models for cross domain and disparate data and penned an in-depth analysis of model's performances. Moreover, an explainability of language models coherent with pretraining is presented which verifies the context capturing capabilities of these models through a model agnostic approach. The experimental results establish new state-of-the-art for Yelp 2013 rating classification task and Financial Phrasebank sentiment detection task with 69% accuracy and 88.2% accuracy respectively. Finally, the study conferred here can greatly assist industry researchers in choosing the language model effectively in terms of performance or compute efficiency.