 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Channel Multi-Attention in ViT for Biometric Authentication using Forehead Subcutaneous Vein Pattern and Periocular Pattern
Dec 26, 2024



Traditional biometric systems, like face and fingerprint recognition, have encountered significant setbacks due to wearing face masks and hygiene concerns. To meet the challenges of the partially covered face due to face masks and hygiene concerns of fingerprint recognition, this paper proposes a novel dual-channel multi-attention Vision Transformer (ViT) framework for biometric authentication using forehead subcutaneous vein patterns and periocular patterns, offering a promising alternative to traditional methods, capable of performing well even with face masks and without any physical touch. The proposed framework leverages a dual-channel ViT architecture, designed to handle two distinct biometric traits. It can capture long-range dependencies of independent features from the vein and periocular patterns. A custom classifier is then designed to integrate the independently extracted features, producing a final class prediction. The performance of the proposed algorithm was rigorously evaluated using the Forehead Subcutaneous Vein Pattern and Periocular Biometric Pattern (FSVP-PBP) database. The results demonstrated the superiority of the algorithm over state-of-the-art methods, achieving remarkable classification accuracy of $99.3 \pm 0.02\%$ with the combined vein and periocular patterns.
Using a Bi-directional LSTM Model with Attention Mechanism trained on MIDI Data for Generating Unique Music
Nov 02, 2020


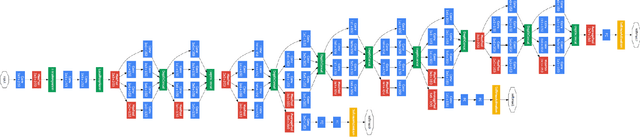
Generating music is an interesting and challenging problem in the field of machine learning. Mimicking human creativity has been popular in recent years, especially in the field of computer vision and image processing. With the advent of GANs, it is possible to generate new similar images, based on trained data. But this cannot be done for music similarly, as music has an extra temporal dimension. So it is necessary to understand how music is represented in digital form. When building models that perform this generative task, the learning and generation part is done in some high-level representation such as MIDI (Musical Instrument Digital Interface) or scores. This paper proposes a bi-directional LSTM (Long short-term memory) model with attention mechanism capable of generating similar type of music based on MIDI data. The music generated by the model follows the theme/style of the music the model is trained on. Also, due to the nature of MIDI, the tempo, instrument, and other parameters can be defined, and changed, post generation.
A Parallel Approach for Real-Time Face Recognition from a Large Database
Nov 01, 2020

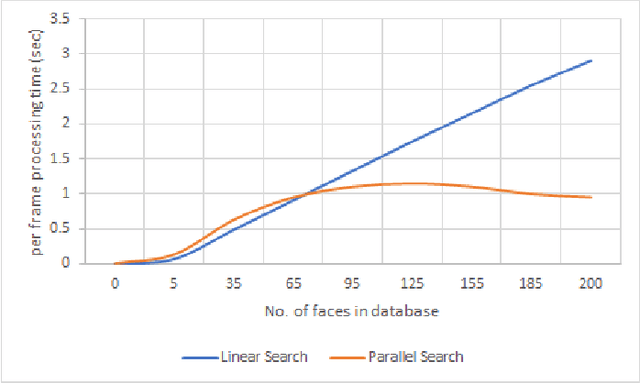
We present a new facial recognition system, capable of identifying a person, provided their likeness has been previously stored in the system, in real time. The system is based on storing and comparing facial embeddings of the subject, and identifying them later within a live video feed. This system is highly accurate, and is able to tag people with their ID in real time. It is able to do so, even when using a database containing thousands of facial embeddings, by using a parallelized searching technique. This makes the system quite fast and allows it to be highly scalable.