 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs and Agentic AI in Insurance Decision-Making: Opportunities and Challenges For Africa
Aug 20, 2025In this work, we highlight the transformative potential of Artificial Intelligence (AI), particularly Large Language Models (LLMs) and agentic AI, in the insurance sector. We consider and emphasize the unique opportunities, challenges, and potential pathways in insurance amid rapid performance improvements, increased open-source access, decreasing deployment costs, and the complexity of LLM or agentic AI frameworks. To bring it closer to home, we identify critical gaps in the African insurance market and highlight key local efforts, players, and partnership opportunities. Finally, we call upon actuaries, insurers, regulators, and tech leaders to a collaborative effort aimed at creating inclusive, sustainable, and equitable AI strategies and solutions: by and for Africans.
Balancing Accuracy, Calibration, and Efficiency in Active Learning with Vision Transformers Under Label Noise
May 07, 2025Fine-tuning pre-trained convolutional neural networks on ImageNet for downstream tasks is well-established. Still, the impact of model size on the performance of vision transformers in similar scenarios, particularly under label noise, remains largely unexplored. Given the utility and versatility of transformer architectures, this study investigates their practicality under low-budget constraints and noisy labels. We explore how classification accuracy and calibration are affected by symmetric label noise in active learning settings, evaluating four vision transformer configurations (Base and Large with 16x16 and 32x32 patch sizes) and three Swin Transformer configurations (Tiny, Small, and Base) on CIFAR10 and CIFAR100 datasets, under varying label noise rates. Our findings show that larger ViT models (ViTl32 in particular) consistently outperform their smaller counterparts in both accuracy and calibration, even under moderate to high label noise, while Swin Transformers exhibit weaker robustness across all noise levels. We find that smaller patch sizes do not always lead to better performance, as ViTl16 performs consistently worse than ViTl32 while incurring a higher computational cost. We also find that information-based Active Learning strategies only provide meaningful accuracy improvements at moderate label noise rates, but they result in poorer calibration compared to models trained on randomly acquired labels, especially at high label noise rates. We hope these insights provide actionable guidance for practitioners looking to deploy vision transformers in resource-constrained environments, where balancing model complexity, label noise, and compute efficiency is critical in model fine-tuning or distillation.
GCI-ViTAL: Gradual Confidence Improvement with Vision Transformers for Active Learning on Label Noise
Nov 08, 2024



Active learning aims to train accurate classifiers while minimizing labeling costs by strategically selecting informative samples for annotation. This study focuses on image classification tasks, comparing AL methods on CIFAR10, CIFAR100, Food101, and the Chest X-ray datasets under varying label noise rates. We investigate the impact of model architecture by comparing Convolutional Neural Networks (CNNs) and Vision Transformer (ViT)-based models. Additionally, we propose a novel deep active learning algorithm, GCI-ViTAL, designed to be robust to label noise. GCI-ViTAL utilizes prediction entropy and the Frobenius norm of last-layer attention vectors compared to class-centric clean set attention vectors. Our method identifies samples that are both uncertain and semantically divergent from typical images in their assigned class. This allows GCI-ViTAL to select informative data points even in the presence of label noise while flagging potentially mislabeled candidates. Label smoothing is applied to train a model that is not overly confident about potentially noisy labels. We evaluate GCI-ViTAL under varying levels of symmetric label noise and compare it to five other AL strategies. Our results demonstrate that using ViTs leads to significant performance improvements over CNNs across all AL strategies, particularly in noisy label settings. We also find that using the semantic information of images as label grounding helps in training a more robust model under label noise. Notably, we do not perform extensive hyperparameter tuning, providing an out-of-the-box comparison that addresses the common challenge practitioners face in selecting models and active learning strategies without an exhaustive literature review on training and fine-tuning vision models on real-world application data.
Assistive Image Annotation Systems with Deep Learning and Natural Language Capabilities: A Review
Jun 28, 2024While supervised learning has achieved significant success in computer vision tasks, acquiring high-quality annotated data remains a bottleneck. This paper explores both scholarly and non-scholarly works in AI-assistive deep learning image annotation systems that provide textual suggestions, captions, or descriptions of the input image to the annotator. This potentially results in higher annotation efficiency and quality. Our exploration covers annotation for a range of computer vision tasks including image classification, object detection, regression, instance, semantic segmentation, and pose estimation. We review various datasets and how they contribute to the training and evaluation of AI-assistive annotation systems. We also examine methods leveraging neuro-symbolic learning, deep active learning, and self-supervised learning algorithms that enable semantic image understanding and generate free-text output. These include image captioning, visual question answering, and multi-modal reasoning. Despite the promising potential, there is limited publicly available work on AI-assistive image annotation with textual output capabilities. We conclude by suggesting future research directions to advance this field, emphasizing the need for more publicly accessible datasets and collaborative efforts between academia and industry.
FishNet: Deep Neural Networks for Low-Cost Fish Stock Estimation
Mar 16, 2024

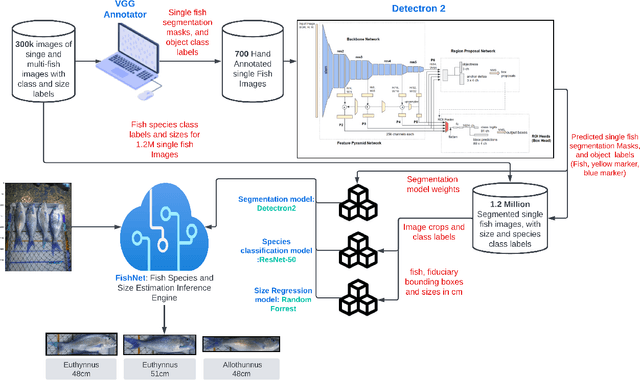

Fish stock assessment often involves manual fish counting by taxonomy specialists, which is both time-consuming and costly. We propose an automated computer vision system that performs both taxonomic classification and fish size estimation from images taken with a low-cost digital camera. The system first performs object detection and segmentation using a Mask R-CNN to identify individual fish from images containing multiple fish, possibly consisting of different species. Then each fish species is classified and the predicted length using separate machine learning models. These models are trained on a dataset of 50,000 hand-annotated images containing 163 different fish species, ranging in length from 10cm to 250cm. Evaluated on held-out test data, our system achieves a $92\%$ intersection over union on the fish segmentation task, a $89\%$ top-1 classification accuracy on single fish species classification, and a $2.3$~cm mean error on the fish length estimation task.
Deep Active Learning in the Presence of Label Noise: A Survey
Feb 22, 2023



Deep active learning has emerged as a powerful tool for training deep learning models within a predefined labeling budget. These models have achieved performances comparable to those trained in an offline setting. However, deep active learning faces substantial issues when dealing with classification datasets containing noisy labels. In this literature review, we discuss the current state of deep active learning in the presence of label noise, highlighting unique approaches, their strengths, and weaknesses. With the recent success of vision transformers in image classification tasks, we provide a brief overview and consider how the transformer layers and attention mechanisms can be used to enhance diversity, importance, and uncertainty-based selection in queries sent to an oracle for labeling. We further propose exploring contrastive learning methods to derive good image representations that can aid in selecting high-value samples for labeling in an active learning setting. We also highlight the need for creating unified benchmarks and standardized datasets for deep active learning in the presence of label noise for image classification to promote the reproducibility of research. The review concludes by suggesting avenues for future research in this area.
Comparision Of Adversarial And Non-Adversarial LSTM Music Generative Models
Nov 01, 2022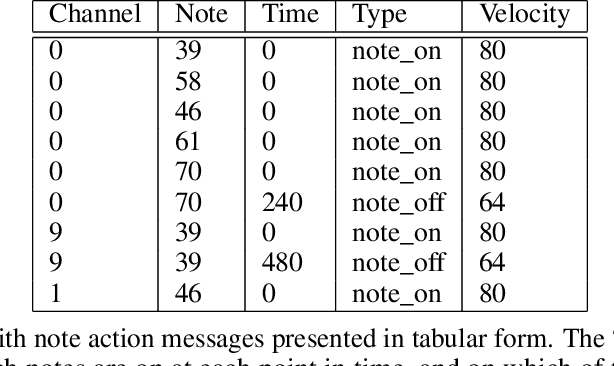
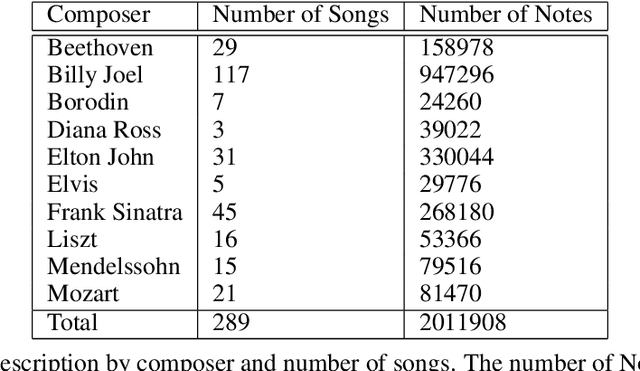
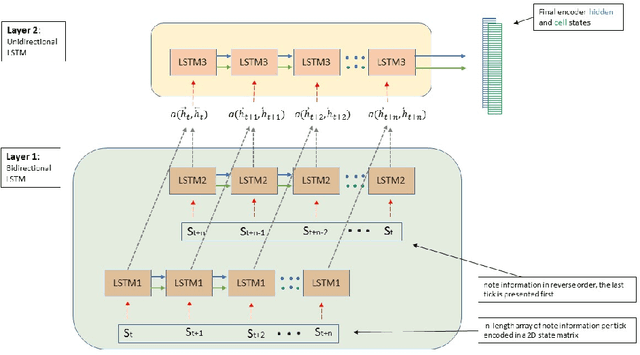
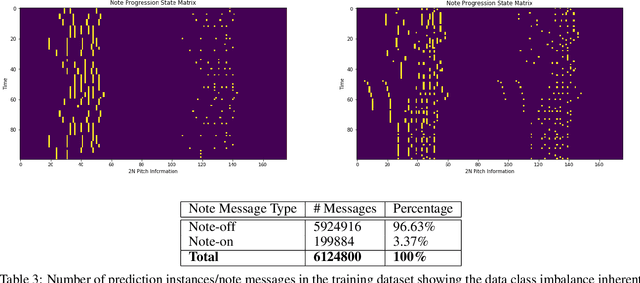
Algorithmic music composition is a way of composing musical pieces with minimal to no human intervention. While recurrent neural networks are traditionally applied to many sequence-to-sequence prediction tasks, including successful implementations of music composition, their standard supervised learning approach based on input-to-output mapping leads to a lack of note variety. These models can therefore be seen as potentially unsuitable for tasks such as music generation. Generative adversarial networks learn the generative distribution of data and lead to varied samples. This work implements and compares adversarial and non-adversarial training of recurrent neural network music composers on MIDI data. The resulting music samples are evaluated by human listeners, their preferences recorded. The evaluation indicates that adversarial training produces more aesthetically pleasing music.