 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying COVID-19 Related Tweets for Fake News Detection and Sentiment Analysis with BERT-based Models
Apr 02, 2023The present paper is about the participation of our team "techno" on CERIST'22 shared tasks. We used an available dataset "task1.c" related to covid-19 pandemic. It comprises 4128 tweets for sentiment analysis task and 8661 tweets for fake news detection task. We used natural language processing tools with the combination of the most renowned pre-trained language models BERT (Bidirectional Encoder Representations from Transformers). The results shows the efficacy of pre-trained language models as we attained an accuracy of 0.93 for the sentiment analysis task and 0.90 for the fake news detection task.
Concept Based vs. Pseudo Relevance Feedback Performance Evaluation for Information Retrieval System
Mar 18, 2014
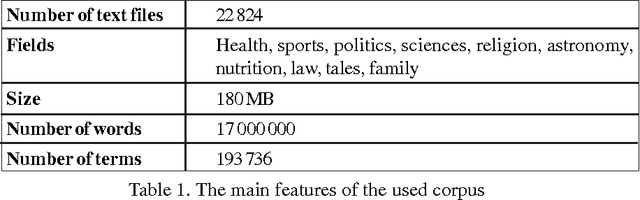
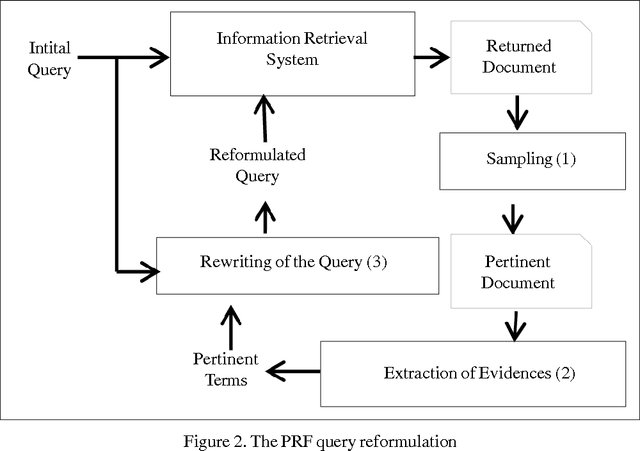
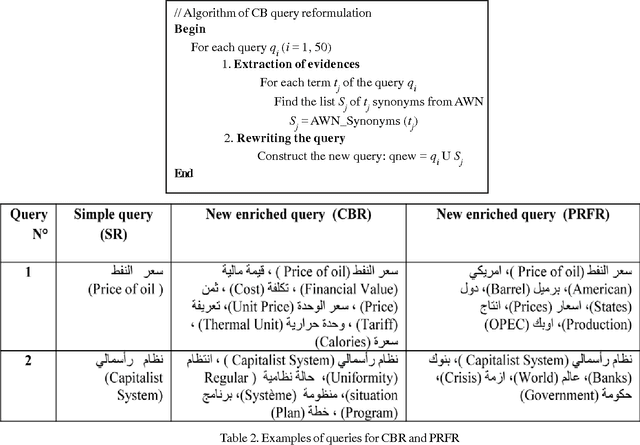
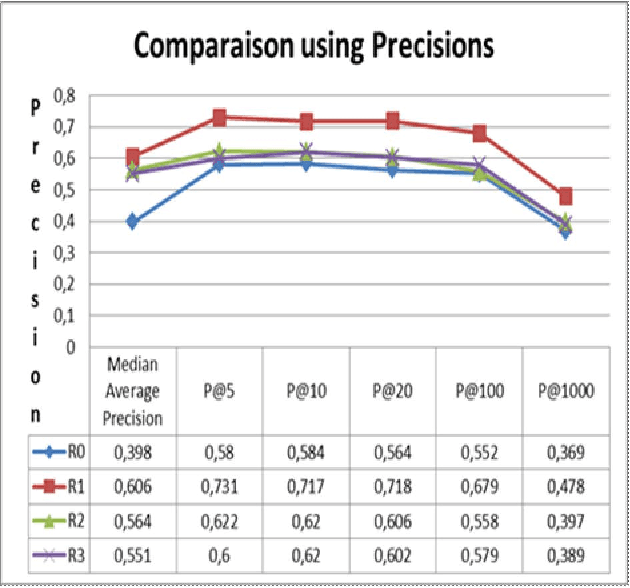
This article evaluates the performance of two techniques for query reformulation in a system for information retrieval, namely, the concept based and the pseudo relevance feedback reformulation. The experiments performed on a corpus of Arabic text have allowed us to compare the contribution of these two reformulation techniques in improving the performance of an information retrieval system for Arabic texts.
* arXiv admin note: substantial text overlap with arXiv:1306.3955 by other authors
Using Arabic Wordnet for semantic indexation in information retrieval system
Jun 19, 2013

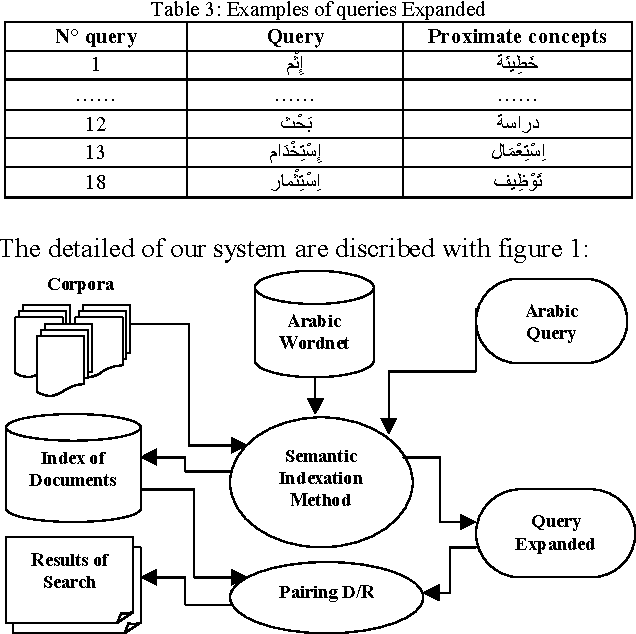
In the context of arabic Information Retrieval Systems (IRS) guided by arabic ontology and to enable those systems to better respond to user requirements, this paper aims to representing documents and queries by the best concepts extracted from Arabic Wordnet. Identified concepts belonging to Arabic WordNet synsets are extracted from documents and queries, and those having a single sense are expanded. The expanded query is then used by the IRS to retrieve the relevant documents searched. Our experiments are based primarily on a medium size corpus of arabic text. The results obtained shown us that there are a global improvement in the performance of the arabic IRS.
* 6 pages,2 figures,7 tables