 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-BRIGHT: A Multi-Task Multimodal Benchmark for Reasoning-Intensive Retrieval
Jan 15, 2026Existing retrieval benchmarks primarily consist of text-based queries where keyword or semantic matching is usually sufficient. Many real-world queries contain multimodal elements, particularly, images such as diagrams, charts, and screenshots that require intensive reasoning to identify relevant documents. To address this gap, we introduce MM-BRIGHT, the first multimodal benchmark for reasoning-intensive retrieval. Our dataset consists of 2,803 real-world queries spanning 29 diverse technical domains, with four tasks of increasing complexity: text-to-text, multimodal-to-text, multimodal-to-image, and multimodal-to-multimodal retrieval. Extensive evaluation reveals that state-of-the-art models struggle across all tasks: BM25 achieves only 8.5 nDCG@10 on text-only retrieval, while the best multimodal model Nomic-Vision reaches just 27.6 nDCG@10 on multimodal-to-text retrieval actually underperforming the best text-only model (DiVeR: 32.2). These results highlight substantial headroom and position MM-BRIGHT as a testbed for next-generation retrieval models that better integrate visual reasoning. Our code and data are available at https://github.com/mm-bright/MM-BRIGHT. See also our official website: https://mm-bright.github.io/.
TEMPO: A Realistic Multi-Domain Benchmark for Temporal Reasoning-Intensive Retrieval
Jan 14, 2026Existing temporal QA benchmarks focus on simple fact-seeking queries from news corpora, while reasoning-intensive retrieval benchmarks lack temporal grounding. However, real-world information needs often require reasoning about temporal evolution and synthesizing evidence across time periods. We introduce TEMPO, the first benchmark combining temporal reasoning with reasoning-intensive retrieval across 13 domains. TEMPO features: (1) 1,730 complex queries requiring deep temporal reasoning such as tracking changes, identifying trends, or comparing cross-period evidence; (2) step-wise retrieval planning with 3,976 decomposed steps and gold documents mapped to each step for multi-hop evaluation; and (3) novel temporal metrics including Temporal Coverage@k and Temporal Precision@k measuring whether results span required time periods. Evaluation of 12 retrieval systems reveals substantial challenges: the best model (DiVeR) achieves only 32.0 NDCG@10 and 71.4\% Temporal Coverage@10, demonstrating difficulty in retrieving temporally complete evidence. We believe TEMPO provides a challenging benchmark for improving temporal reasoning in retrieval and RAG systems. Our code and data are available at https://github.com/tempo-bench/Tempo. See also our official website: https://tempo-bench.github.io/.
RankArena: A Unified Platform for Evaluating Retrieval, Reranking and RAG with Human and LLM Feedback
Aug 07, 2025Evaluating the quality of retrieval-augmented generation (RAG) and document reranking systems remains challenging due to the lack of scalable, user-centric, and multi-perspective evaluation tools. We introduce RankArena, a unified platform for comparing and analysing the performance of retrieval pipelines, rerankers, and RAG systems using structured human and LLM-based feedback as well as for collecting such feedback. RankArena supports multiple evaluation modes: direct reranking visualisation, blind pairwise comparisons with human or LLM voting, supervised manual document annotation, and end-to-end RAG answer quality assessment. It captures fine-grained relevance feedback through both pairwise preferences and full-list annotations, along with auxiliary metadata such as movement metrics, annotation time, and quality ratings. The platform also integrates LLM-as-a-judge evaluation, enabling comparison between model-generated rankings and human ground truth annotations. All interactions are stored as structured evaluation datasets that can be used to train rerankers, reward models, judgment agents, or retrieval strategy selectors. Our platform is publicly available at https://rankarena.ngrok.io/, and the Demo video is provided https://youtu.be/jIYAP4PaSSI.
From Retrieval to Generation: Comparing Different Approaches
Feb 27, 2025Knowledge-intensive tasks, particularly open-domain question answering (ODQA), document reranking, and retrieval-augmented language modeling, require a balance between retrieval accuracy and generative flexibility. Traditional retrieval models such as BM25 and Dense Passage Retrieval (DPR), efficiently retrieve from large corpora but often lack semantic depth. Generative models like GPT-4-o provide richer contextual understanding but face challenges in maintaining factual consistency. In this work, we conduct a systematic evaluation of retrieval-based, generation-based, and hybrid models, with a primary focus on their performance in ODQA and related retrieval-augmented tasks. Our results show that dense retrievers, particularly DPR, achieve strong performance in ODQA with a top-1 accuracy of 50.17\% on NQ, while hybrid models improve nDCG@10 scores on BEIR from 43.42 (BM25) to 52.59, demonstrating their strength in document reranking. Additionally, we analyze language modeling tasks using WikiText-103, showing that retrieval-based approaches like BM25 achieve lower perplexity compared to generative and hybrid methods, highlighting their utility in retrieval-augmented generation. By providing detailed comparisons and practical insights into the conditions where each approach excels, we aim to facilitate future optimizations in retrieval, reranking, and generative models for ODQA and related knowledge-intensive applications.
Rankify: A Comprehensive Python Toolkit for Retrieval, Re-Ranking, and Retrieval-Augmented Generation
Feb 04, 2025
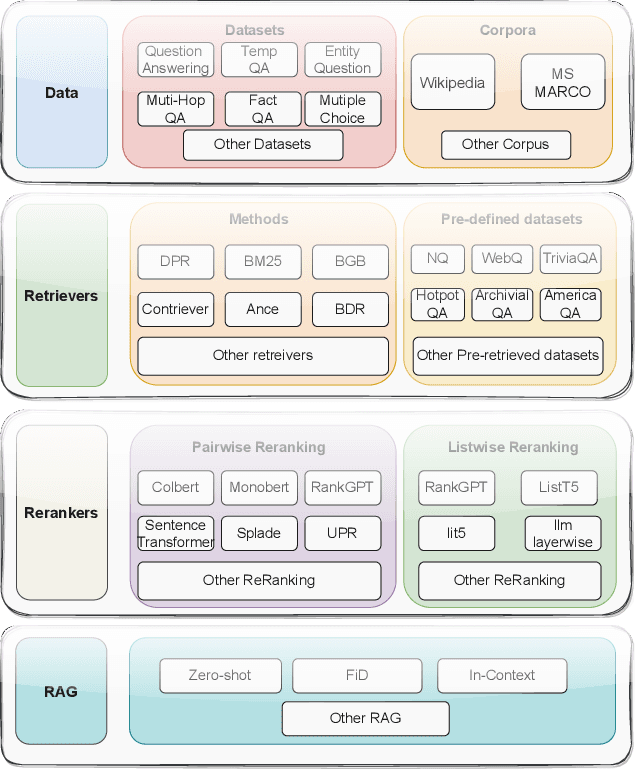
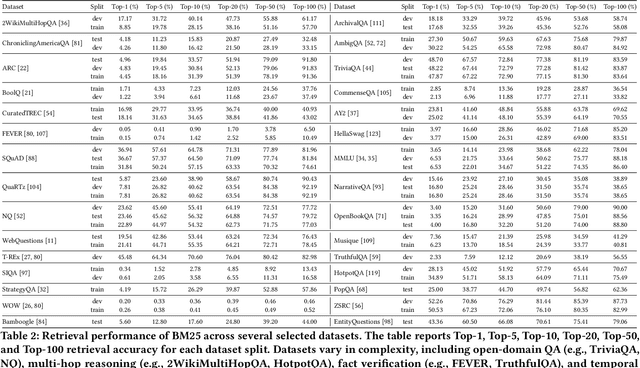
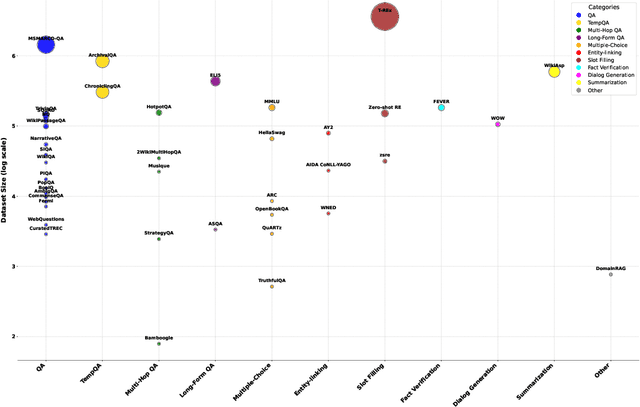
Retrieval, re-ranking, and retrieval-augmented generation (RAG) are critical components of modern natural language processing (NLP) applications in information retrieval, question answering, and knowledge-based text generation. However, existing solutions are often fragmented, lacking a unified framework that easily integrates these essential processes. The absence of a standardized implementation, coupled with the complexity of retrieval and re-ranking workflows, makes it challenging for researchers to compare and evaluate different approaches in a consistent environment. While existing toolkits such as Rerankers and RankLLM provide general-purpose reranking pipelines, they often lack the flexibility required for fine-grained experimentation and benchmarking. In response to these challenges, we introduce \textbf{Rankify}, a powerful and modular open-source toolkit designed to unify retrieval, re-ranking, and RAG within a cohesive framework. Rankify supports a wide range of retrieval techniques, including dense and sparse retrievers, while incorporating state-of-the-art re-ranking models to enhance retrieval quality. Additionally, Rankify includes a collection of pre-retrieved datasets to facilitate benchmarking, available at Huggingface (https://huggingface.co/datasets/abdoelsayed/reranking-datasets). To encourage adoption and ease of integration, we provide comprehensive documentation (http://rankify.readthedocs.io/), an open-source implementation on GitHub(https://github.com/DataScienceUIBK/rankify), and a PyPI package for effortless installation(https://pypi.org/project/rankify/). By providing a unified and lightweight framework, Rankify allows researchers and practitioners to advance retrieval and re-ranking methodologies while ensuring consistency, scalability, and ease of use.