 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEFR: A Fast Linear-Time Classifier for Ultra-Low Power Devices
Jun 08, 2020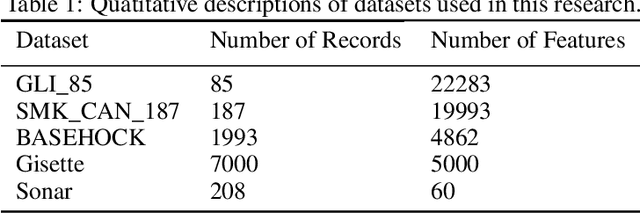
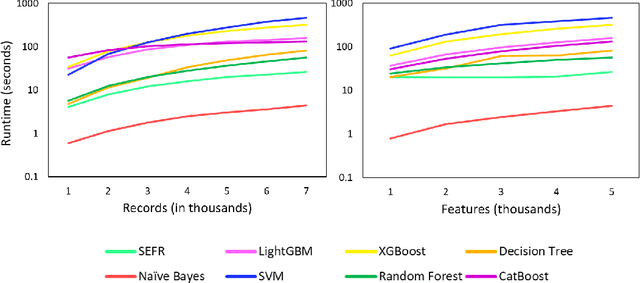
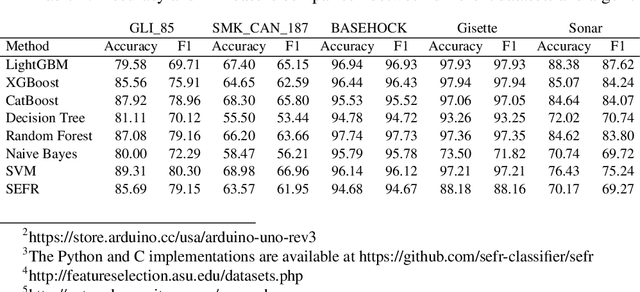
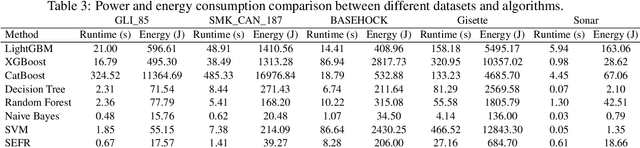
One of the fundamental challenges for running machine learning algorithms on battery-powered devices is the time and energy needed for computation, as these devices have constraints on resources. There are energy-efficient classifier algorithms, but their accuracy is often sacrificed for resource efficiency. Here, we propose an ultra-low power binary classifier, SEFR, with linear time complexity, both in the training and the testing phases. The SEFR method runs by creating a hyperplane to separate two classes. The weights of this hyperplane are calculated using normalization, and then the bias is computed based on the weights. SEFR is comparable to state-of-the-art classifiers in terms of classification accuracy, but its execution time and energy consumption are 11.02% and 8.67% of the average of state-of-the-art and baseline classifiers. The energy and memory consumption of SEFR is very insignificant, and it even can perform both train and test phases on microcontrollers. We have implemented SEFR on Arduino Uno, and on a dataset with 100 records and 100 features, the training time is 195 milliseconds, and testing for 100 records with 100 features takes 0.73 milliseconds. To the best of our knowledge, this is the first multipurpose algorithm specifically devised for learning on ultra-low power devices.
Automated Text Summarization Base on Lexicales Chain and graph Using of WordNet and Wikipedia Knowledge Base
Mar 15, 2012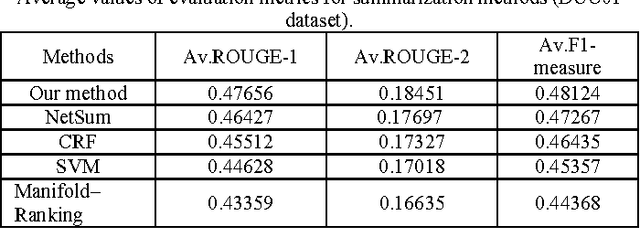
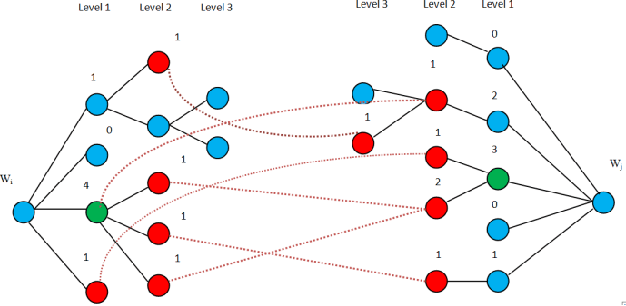
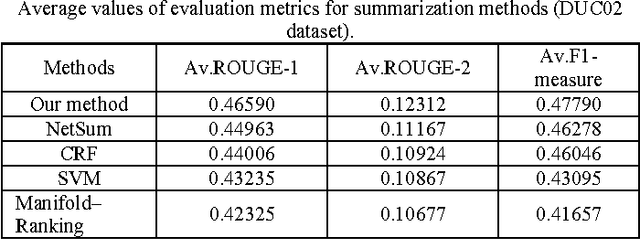
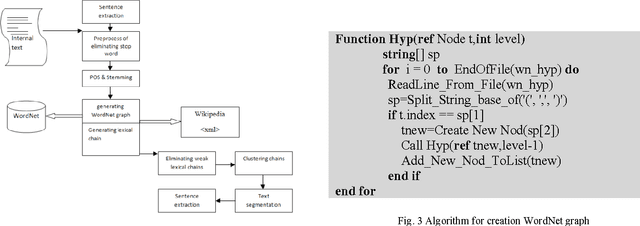
The technology of automatic document summarization is maturing and may provide a solution to the information overload problem. Nowadays, document summarization plays an important role in information retrieval. With a large volume of documents, presenting the user with a summary of each document greatly facilitates the task of finding the desired documents. Document summarization is a process of automatically creating a compressed version of a given document that provides useful information to users, and multi-document summarization is to produce a summary delivering the majority of information content from a set of documents about an explicit or implicit main topic. The lexical cohesion structure of the text can be exploited to determine the importance of a sentence/phrase. Lexical chains are useful tools to analyze the lexical cohesion structure in a text .In this paper we consider the effect of the use of lexical cohesion features in Summarization, And presenting a algorithm base on the knowledge base. Ours algorithm at first find the correct sense of any word, Then constructs the lexical chains, remove Lexical chains that less score than other, detects topics roughly from lexical chains, segments the text with respect to the topics and selects the most important sentences. The experimental results on an open benchmark datasets from DUC01 and DUC02 show that our proposed approach can improve the performance compared to sate-of-the-art summarization approaches.