 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPVNet: Learning Implicit Point-Voxel Features for Open-Surface 3D Reconstruction
Nov 05, 2023

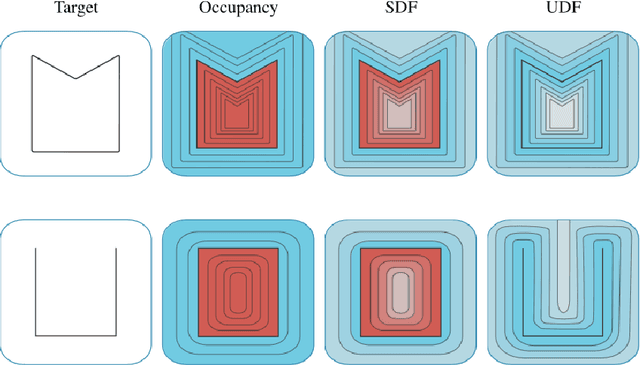
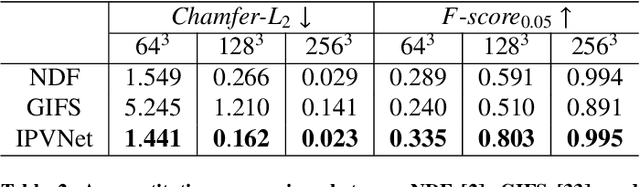
Reconstruction of 3D open surfaces (e.g., non-watertight meshes) is an underexplored area of computer vision. Recent learning-based implicit techniques have removed previous barriers by enabling reconstruction in arbitrary resolutions. Yet, such approaches often rely on distinguishing between the inside and outside of a surface in order to extract a zero level set when reconstructing the target. In the case of open surfaces, this distinction often leads to artifacts such as the artificial closing of surface gaps. However, real-world data may contain intricate details defined by salient surface gaps. Implicit functions that regress an unsigned distance field have shown promise in reconstructing such open surfaces. Nonetheless, current unsigned implicit methods rely on a discretized representation of the raw data. This not only bounds the learning process to the representation's resolution, but it also introduces outliers in the reconstruction. To enable accurate reconstruction of open surfaces without introducing outliers, we propose a learning-based implicit point-voxel model (IPVNet). IPVNet predicts the unsigned distance between a surface and a query point in 3D space by leveraging both raw point cloud data and its discretized voxel counterpart. Experiments on synthetic and real-world public datasets demonstrates that IPVNet outperforms the state of the art while producing far fewer outliers in the resulting reconstruction.
LIST: Learning Implicitly from Spatial Transformers for Single-View 3D Reconstruction
Jul 23, 2023



Accurate reconstruction of both the geometric and topological details of a 3D object from a single 2D image embodies a fundamental challenge in computer vision. Existing explicit/implicit solutions to this problem struggle to recover self-occluded geometry and/or faithfully reconstruct topological shape structures. To resolve this dilemma, we introduce LIST, a novel neural architecture that leverages local and global image features to accurately reconstruct the geometric and topological structure of a 3D object from a single image. We utilize global 2D features to predict a coarse shape of the target object and then use it as a base for higher-resolution reconstruction. By leveraging both local 2D features from the image and 3D features from the coarse prediction, we can predict the signed distance between an arbitrary point and the target surface via an implicit predictor with great accuracy. Furthermore, our model does not require camera estimation or pixel alignment. It provides an uninfluenced reconstruction from the input-view direction. Through qualitative and quantitative analysis, we show the superiority of our model in reconstructing 3D objects from both synthetic and real-world images against the state of the art.
Automated Reconstruction of 3D Open Surfaces from Sparse Point Clouds
Oct 26, 2022Real-world 3D data may contain intricate details defined by salient surface gaps. Automated reconstruction of these open surfaces (e.g., non-watertight meshes) is a challenging problem for environment synthesis in mixed reality applications. Current learning-based implicit techniques can achieve high fidelity on closed-surface reconstruction. However, their dependence on the distinction between the inside and outside of a surface makes them incapable of reconstructing open surfaces. Recently, a new class of implicit functions have shown promise in reconstructing open surfaces by regressing an unsigned distance field. Yet, these methods rely on a discretized representation of the raw data, which loses important surface details and can lead to outliers in the reconstruction. We propose IPVNet, a learning-based implicit model that predicts the unsigned distance between a surface and a query point in 3D space by leveraging both raw point cloud data and its discretized voxel counterpart. Experiments on synthetic and real-world public datasets demonstrates that IPVNet outperforms the state of the art while producing far fewer outliers in the reconstruction.
A Progressive Conditional Generative Adversarial Network for Generating Dense and Colored 3D Point Clouds
Oct 12, 2020
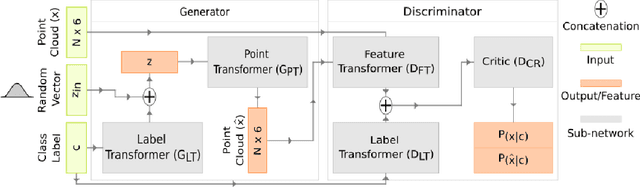
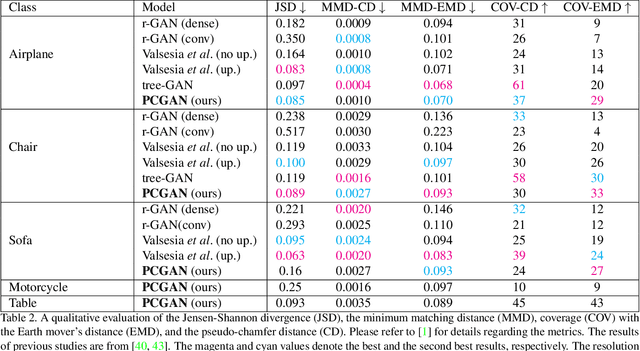
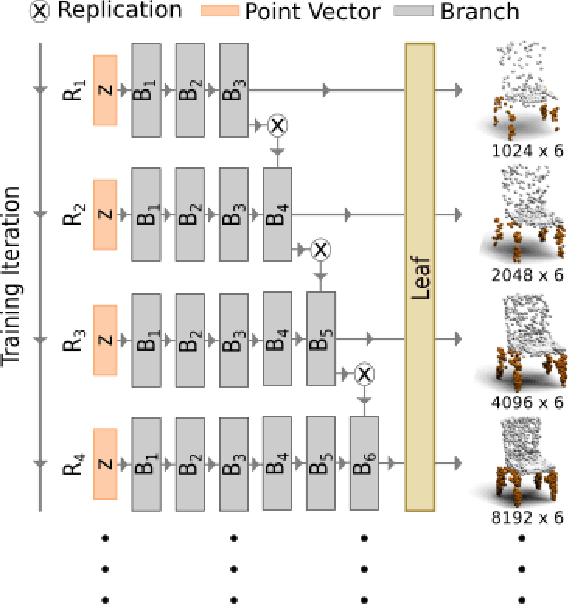
In this paper, we introduce a novel conditional generative adversarial network that creates dense 3D point clouds, with color, for assorted classes of objects in an unsupervised manner. To overcome the difficulty of capturing intricate details at high resolutions, we propose a point transformer that progressively grows the network through the use of graph convolutions. The network is composed of a leaf output layer and an initial set of branches. Every training iteration evolves a point vector into a point cloud of increasing resolution. After a fixed number of iterations, the number of branches is increased by replicating the last branch. Experimental results show that our network is capable of learning and mimicking a 3D data distribution, and produces colored point clouds with fine details at multiple resolutions.