 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling hyperparameter optimization in sequential autoencoders for spiking neural data
Aug 22, 2019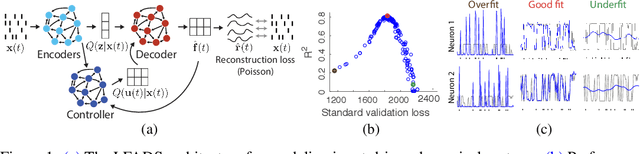


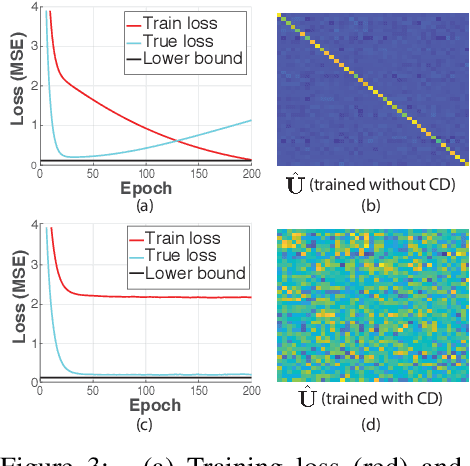
Continuing advances in neural interfaces have enabled simultaneous monitoring of spiking activity from hundreds to thousands of neurons. To interpret these large-scale data, several methods have been proposed to infer latent dynamic structure from high-dimensional datasets. One recent line of work uses recurrent neural networks in a sequential autoencoder (SAE) framework to uncover dynamics. SAEs are an appealing option for modeling nonlinear dynamical systems, and enable a precise link between neural activity and behavior on a single-trial basis. However, the very large parameter count and complexity of SAEs relative to other models has caused concern that SAEs may only perform well on very large training sets. We hypothesized that with a method to systematically optimize hyperparameters (HPs), SAEs might perform well even in cases of limited training data. Such a breakthrough would greatly extend their applicability. However, we find that SAEs applied to spiking neural data are prone to a particular form of overfitting that cannot be detected using standard validation metrics, which prevents standard HP searches. We develop and test two potential solutions: an alternate validation method ("sample validation") and a novel regularization method ("coordinated dropout"). These innovations prevent overfitting quite effectively, and allow us to test whether SAEs can achieve good performance on limited data through large-scale HP optimization. When applied to data from motor cortex recorded while monkeys made reaches in various directions, large-scale HP optimization allowed SAEs to better maintain performance for small dataset sizes. Our results should greatly extend the applicability of SAEs in extracting latent dynamics from sparse, multidimensional data, such as neural population spiking activity.
Unsupervised Spike Sorting Based on Discriminative Subspace Learning
Aug 22, 2014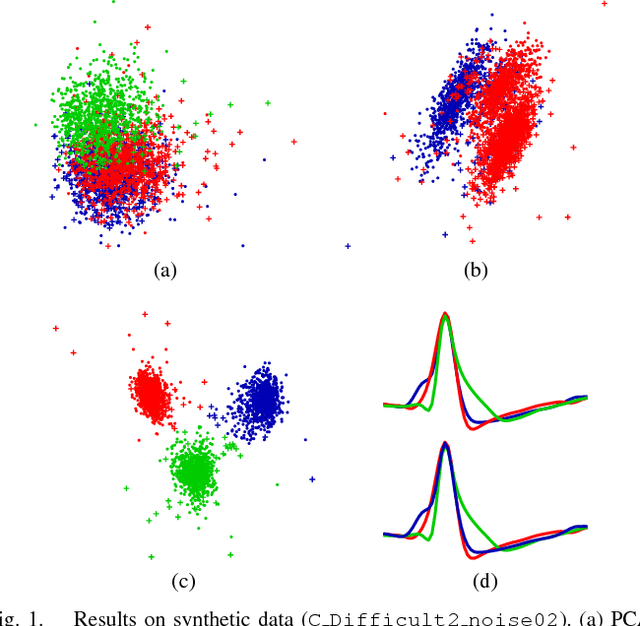
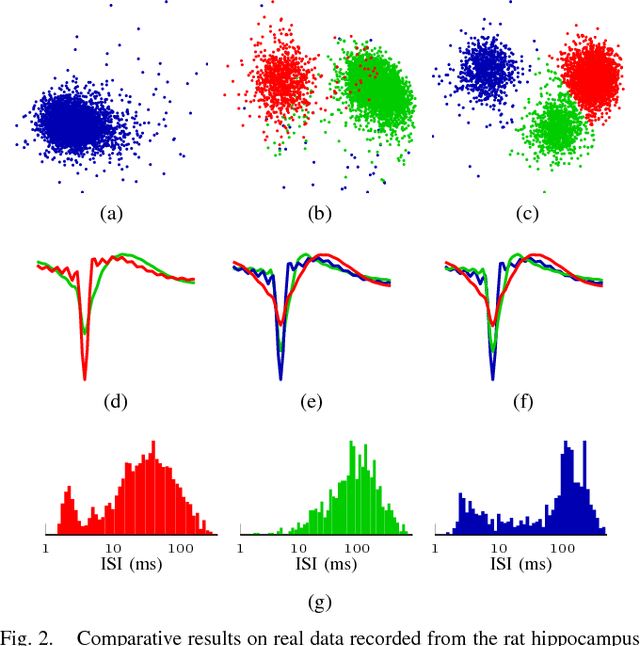

Spike sorting is a fundamental preprocessing step for many neuroscience studies which rely on the analysis of spike trains. In this paper, we present two unsupervised spike sorting algorithms based on discriminative subspace learning. The first algorithm simultaneously learns the discriminative feature subspace and performs clustering. It uses histogram of features in the most discriminative projection to detect the number of neurons. The second algorithm performs hierarchical divisive clustering that learns a discriminative 1-dimensional subspace for clustering in each level of the hierarchy until achieving almost unimodal distribution in the subspace. The algorithms are tested on synthetic and in-vivo data, and are compared against two widely used spike sorting methods. The comparative results demonstrate that our spike sorting methods can achieve substantially higher accuracy in lower dimensional feature space, and they are highly robust to noise. Moreover, they provide significantly better cluster separability in the learned subspace than in the subspace obtained by principal component analysis or wavelet transform.