 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Forest Calibration
Jan 28, 2025The Random Forest (RF) classifier is often claimed to be relatively well calibrated when compared with other machine learning methods. Moreover, the existing literature suggests that traditional calibration methods, such as isotonic regression, do not substantially enhance the calibration of RF probability estimates unless supplied with extensive calibration data sets, which can represent a significant obstacle in cases of limited data availability. Nevertheless, there seems to be no comprehensive study validating such claims and systematically comparing state-of-the-art calibration methods specifically for RF. To close this gap, we investigate a broad spectrum of calibration methods tailored to or at least applicable to RF, ranging from scaling techniques to more advanced algorithms. Our results based on synthetic as well as real-world data unravel the intricacies of RF probability estimates, scrutinize the impacts of hyper-parameters, compare calibration methods in a systematic way. We show that a well-optimized RF performs as well as or better than leading calibration approaches.
Ensemble-based Uncertainty Quantification: Bayesian versus Credal Inference
Jul 21, 2021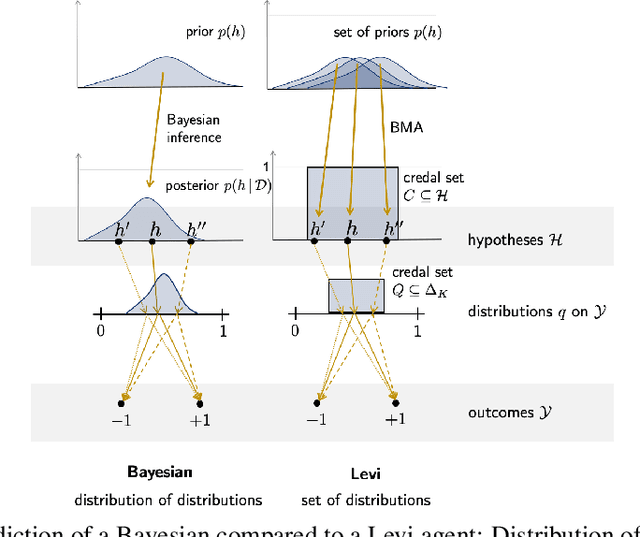

The idea to distinguish and quantify two important types of uncertainty, often referred to as aleatoric and epistemic, has received increasing attention in machine learning research in the last couple of years. In this paper, we consider ensemble-based approaches to uncertainty quantification. Distinguishing between different types of uncertainty-aware learning algorithms, we specifically focus on Bayesian methods and approaches based on so-called credal sets, which naturally suggest themselves from an ensemble learning point of view. For both approaches, we address the question of how to quantify aleatoric and epistemic uncertainty. The effectiveness of corresponding measures is evaluated and compared in an empirical study on classification with a reject option.
Aleatoric and Epistemic Uncertainty with Random Forests
Jan 03, 2020



Due to the steadily increasing relevance of machine learning for practical applications, many of which are coming with safety requirements, the notion of uncertainty has received increasing attention in machine learning research in the last couple of years. In particular, the idea of distinguishing between two important types of uncertainty, often refereed to as aleatoric and epistemic, has recently been studied in the setting of supervised learning. In this paper, we propose to quantify these uncertainties with random forests. More specifically, we show how two general approaches for measuring the learner's aleatoric and epistemic uncertainty in a prediction can be instantiated with decision trees and random forests as learning algorithms in a classification setting. In this regard, we also compare random forests with deep neural networks, which have been used for a similar purpose.