 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian phonemes recognition using PPNet
Dec 17, 2018
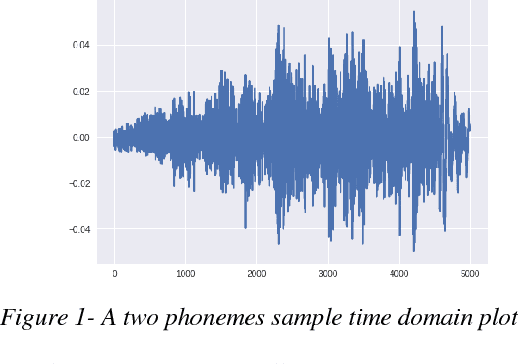
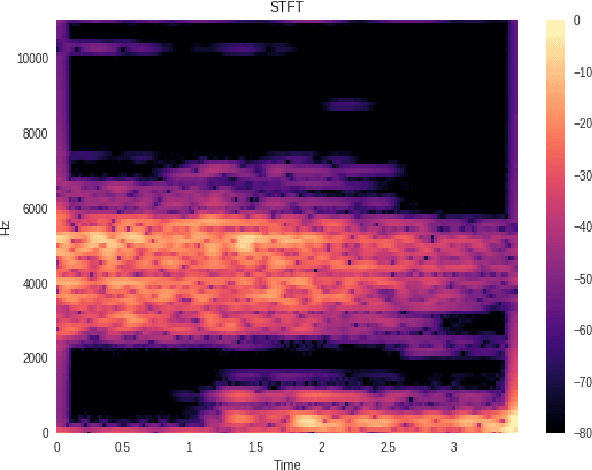
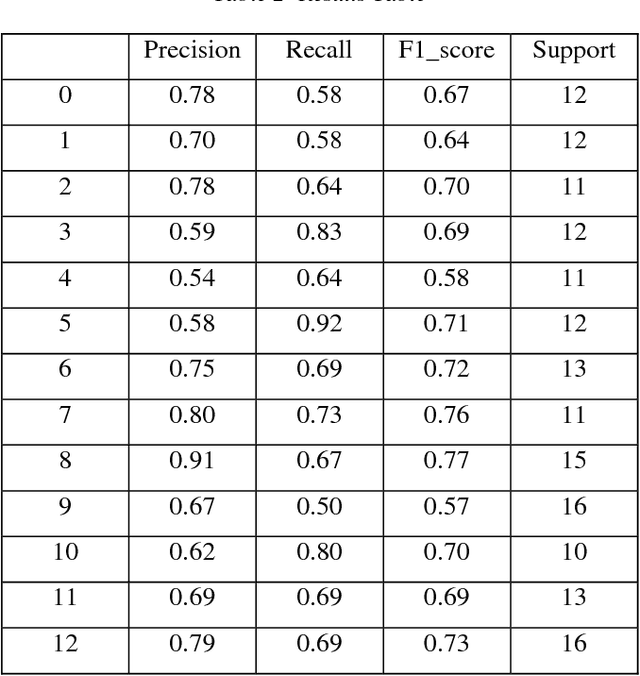
In this paper a new approach for recognition of Persian phonemes on the PCVC speech dataset is proposed. Nowadays deep neural networks are playing main rule in classification tasks. However the best results in speech recognition are not as good as human recognition rate yet. Deep learning techniques are shown their outstanding performance over so many classification tasks like image classification, document classification, etc. Also in some tasks their performance were even better than human. So the reason why ASR (automatic speech recognition) systems are not as good as the human speech recognition system is mostly depend on features of data is fed to deep neural networks. In this research first sound samples are cut for exact extraction of phoneme sounds in 50ms samples. Then phonemes are grouped in 30 groups; Containing 23 consonants, 6 vowels and a silence phoneme. STFT (Short time Fourier transform) is applied on them and Then STFT results are given to PPNet (A new deep convolutional neural network architecture) classifier and a total average of 75.87% accuracy is reached which is the best result ever compared to other algorithms on Separated Persian phonemes (Like in PCVC speech dataset).
Persian Vowel recognition with MFCC and ANN on PCVC speech dataset
Dec 17, 2018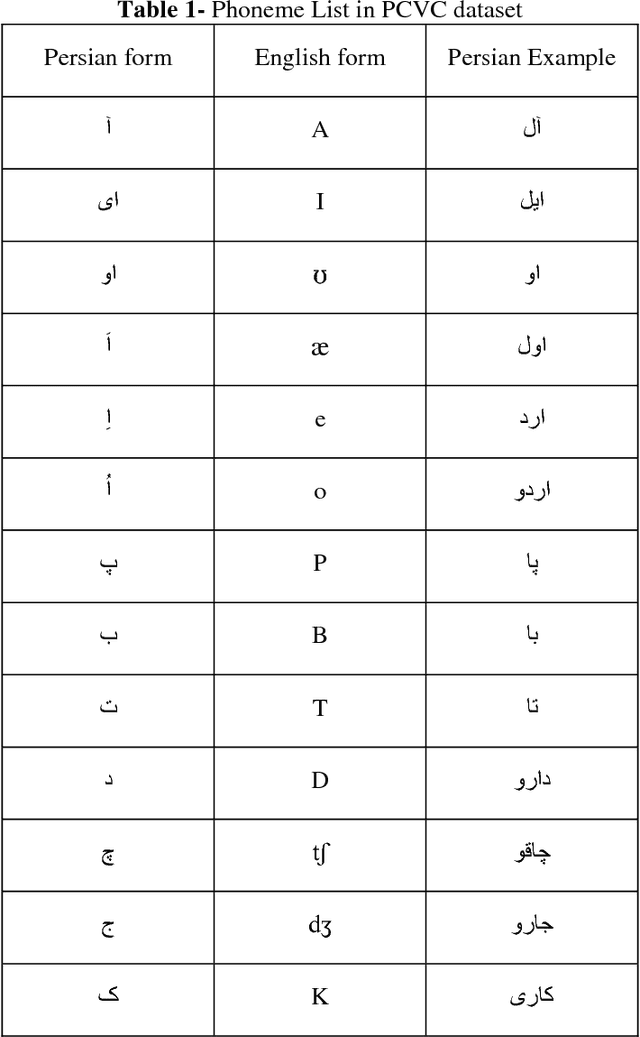
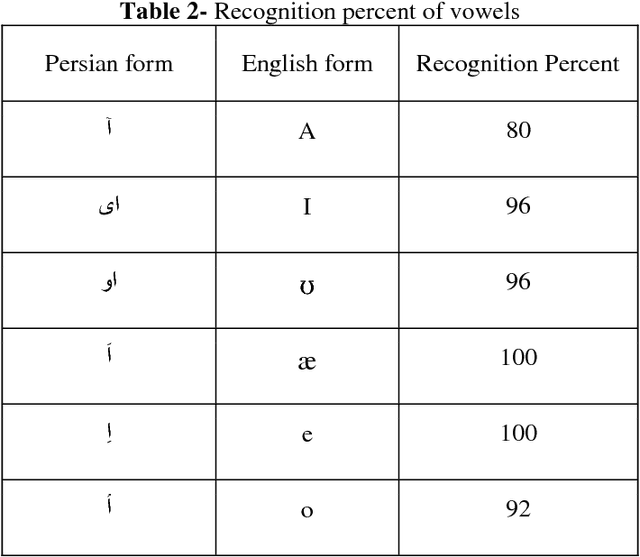
In this paper a new method for recognition of consonant-vowel phonemes combination on a new Persian speech dataset titled as PCVC (Persian Consonant-Vowel Combination) is proposed which is used to recognize Persian phonemes. In PCVC dataset, there are 20 sets of audio samples from 10 speakers which are combinations of 23 consonant and 6 vowel phonemes of Persian language. In each sample, there is a combination of one vowel and one consonant. First, the consonant phoneme is pronounced and just after it, the vowel phoneme is pronounced. Each sound sample is a frame of 2 seconds of audio. In every 2 seconds, there is an average of 0.5 second speech and the rest is silence. In this paper, the proposed method is the implementations of the MFCC (Mel Frequency Cepstrum Coefficients) on every partitioned sound sample. Then, every train sample of MFCC vector is given to a multilayer perceptron feed-forward ANN (Artificial Neural Network) for training process. At the end, the test samples are examined on ANN model for phoneme recognition. After training and testing process, the results are presented in recognition of vowels. Then, the average percent of recognition for vowel phonemes are computed.