 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting the suitable resampling strategy for imbalanced data classification regarding dataset properties
Dec 15, 2021
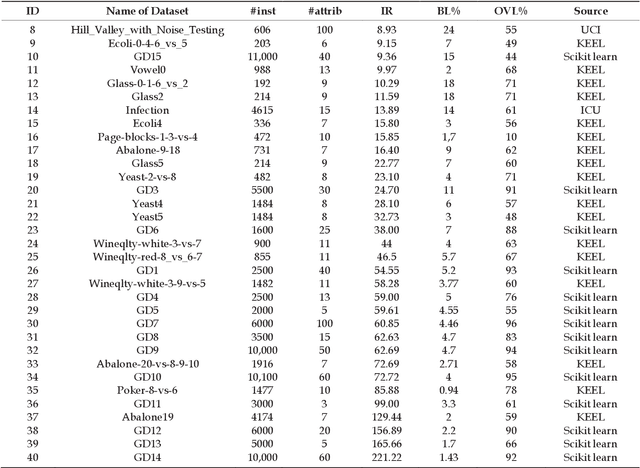
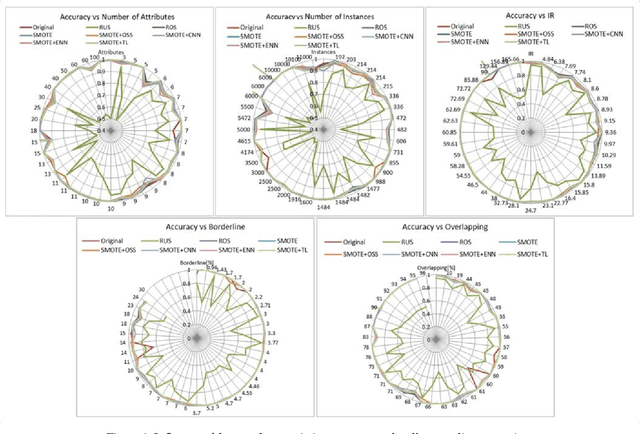
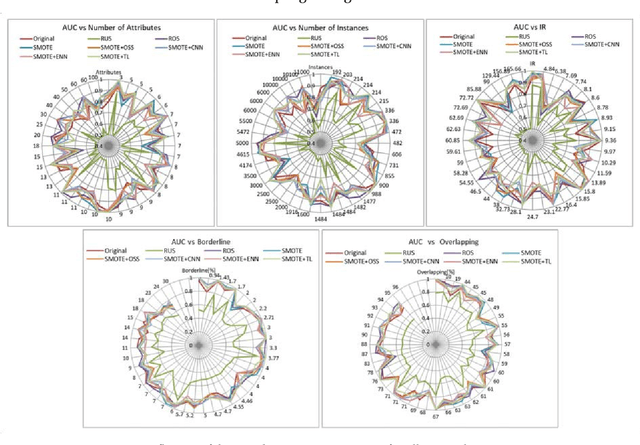
In many application domains such as medicine, information retrieval, cybersecurity, social media, etc., datasets used for inducing classification models often have an unequal distribution of the instances of each class. This situation, known as imbalanced data classification, causes low predictive performance for the minority class examples. Thus, the prediction model is unreliable although the overall model accuracy can be acceptable. Oversampling and undersampling techniques are well-known strategies to deal with this problem by balancing the number of examples of each class. However, their effectiveness depends on several factors mainly related to data intrinsic characteristics, such as imbalance ratio, dataset size and dimensionality, overlapping between classes or borderline examples. In this work, the impact of these factors is analyzed through a comprehensive comparative study involving 40 datasets from different application areas. The objective is to obtain models for automatic selection of the best resampling strategy for any dataset based on its characteristics. These models allow us to check several factors simultaneously considering a wide range of values since they are induced from very varied datasets that cover a broad spectrum of conditions. This differs from most studies that focus on the individual analysis of the characteristics or cover a small range of values. In addition, the study encompasses both basic and advanced resampling strategies that are evaluated by means of eight different performance metrics, including new measures specifically designed for imbalanced data classification. The general nature of the proposal allows the choice of the most appropriate method regardless of the domain, avoiding the search for special purpose techniques that could be valid for the target data.
* Kraiem, M.S., S\'anchez-Hern\'andez, F., Moreno-Garc\'ia, M.N. Selecting the Suitable Resampling Strategy for Imbalanced Data Classification Regarding Dataset Properties. An Approach Based on Association Models. Appl. Sci. 2021, 11(18), 8546, 2021
Predictive Modeling of ICU Healthcare-Associated Infections from Imbalanced Data. Using Ensembles and a Clustering-Based Undersampling Approach
May 07, 2020

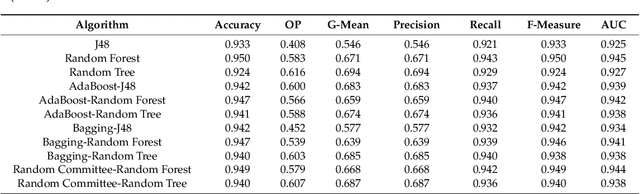
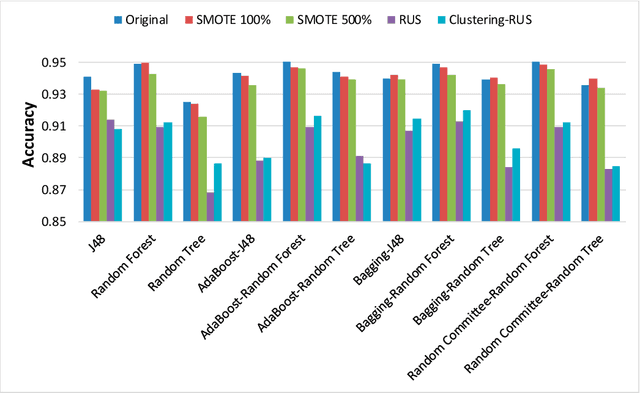
Early detection of patients vulnerable to infections acquired in the hospital environment is a challenge in current health systems given the impact that such infections have on patient mortality and healthcare costs. This work is focused on both the identification of risk factors and the prediction of healthcare-associated infections in intensive-care units by means of machine-learning methods. The aim is to support decision making addressed at reducing the incidence rate of infections. In this field, it is necessary to deal with the problem of building reliable classifiers from imbalanced datasets. We propose a clustering-based undersampling strategy to be used in combination with ensemble classifiers. A comparative study with data from 4616 patients was conducted in order to validate our proposal. We applied several single and ensemble classifiers both to the original dataset and to data preprocessed by means of different resampling methods. The results were analyzed by means of classic and recent metrics specifically designed for imbalanced data classification. They revealed that the proposal is more efficient in comparison with other approaches.