 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Bias Amplification in Graph Neural Network Approaches for Recommender Systems
Jan 18, 2023



Recommender Systems (RSs) are used to provide users with personalized item recommendations and help them overcome the problem of information overload. Currently, recommendation methods based on deep learning are gaining ground over traditional methods such as matrix factorization due to their ability to represent the complex relationships between users and items and to incorporate additional information. The fact that these data have a graph structure and the greater capability of Graph Neural Networks (GNNs) to learn from these structures has led to their successful incorporation into recommender systems. However, the bias amplification issue needs to be investigated while using these algorithms. Bias results in unfair decisions, which can negatively affect the company reputation and financial status due to societal disappointment and environmental harm. In this paper, we aim to comprehensively study this problem through a literature review and an analysis of the behavior against biases of different GNN-based algorithms compared to state-of-the-art methods. We also intend to explore appropriate solutions to tackle this issue with the least possible impact on the model performance.
Selecting the suitable resampling strategy for imbalanced data classification regarding dataset properties
Dec 15, 2021
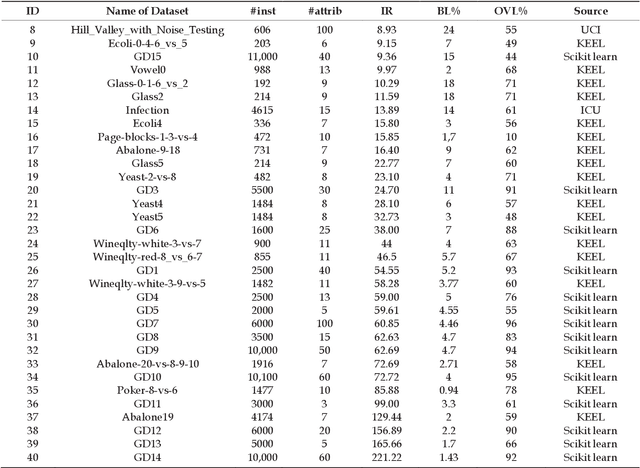
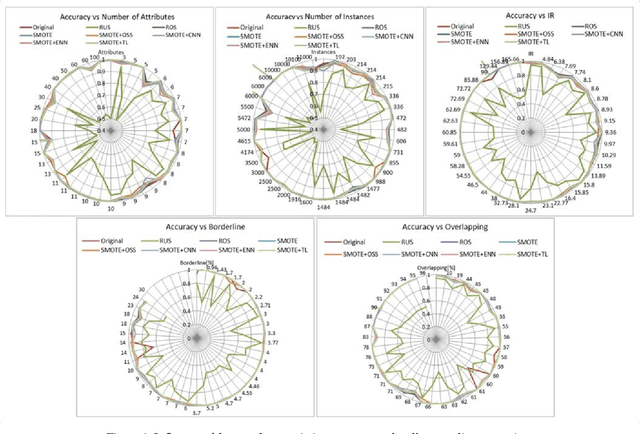
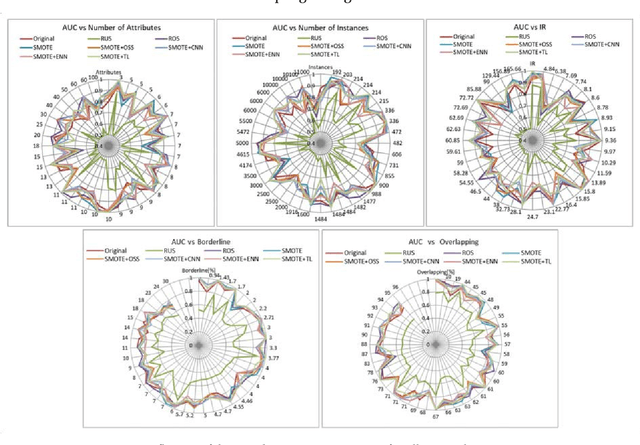
In many application domains such as medicine, information retrieval, cybersecurity, social media, etc., datasets used for inducing classification models often have an unequal distribution of the instances of each class. This situation, known as imbalanced data classification, causes low predictive performance for the minority class examples. Thus, the prediction model is unreliable although the overall model accuracy can be acceptable. Oversampling and undersampling techniques are well-known strategies to deal with this problem by balancing the number of examples of each class. However, their effectiveness depends on several factors mainly related to data intrinsic characteristics, such as imbalance ratio, dataset size and dimensionality, overlapping between classes or borderline examples. In this work, the impact of these factors is analyzed through a comprehensive comparative study involving 40 datasets from different application areas. The objective is to obtain models for automatic selection of the best resampling strategy for any dataset based on its characteristics. These models allow us to check several factors simultaneously considering a wide range of values since they are induced from very varied datasets that cover a broad spectrum of conditions. This differs from most studies that focus on the individual analysis of the characteristics or cover a small range of values. In addition, the study encompasses both basic and advanced resampling strategies that are evaluated by means of eight different performance metrics, including new measures specifically designed for imbalanced data classification. The general nature of the proposal allows the choice of the most appropriate method regardless of the domain, avoiding the search for special purpose techniques that could be valid for the target data.
* Kraiem, M.S., S\'anchez-Hern\'andez, F., Moreno-Garc\'ia, M.N. Selecting the Suitable Resampling Strategy for Imbalanced Data Classification Regarding Dataset Properties. An Approach Based on Association Models. Appl. Sci. 2021, 11(18), 8546, 2021
Dynamic inference of user context through social tag embedding for music recommendation
Sep 23, 2021
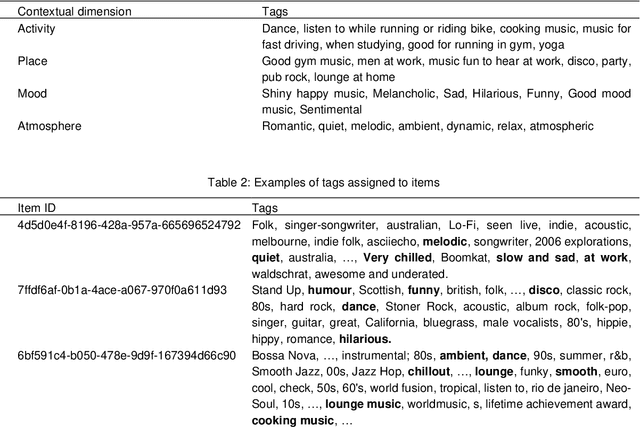
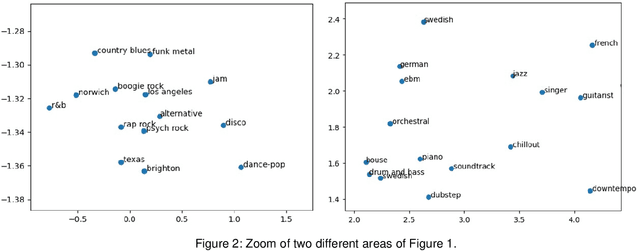
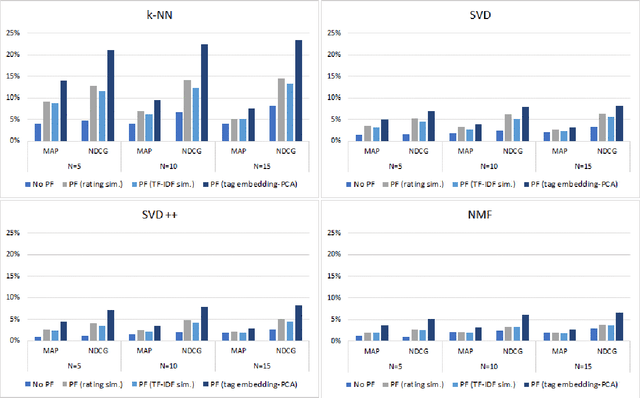
Music listening preferences at a given time depend on a wide range of contextual factors, such as user emotional state, location and activity at listening time, the day of the week, the time of the day, etc. It is therefore of great importance to take them into account when recommending music. However, it is very difficult to develop context-aware recommender systems that consider these factors, both because of the difficulty of detecting some of them, such as emotional state, and because of the drawbacks derived from the inclusion of many factors, such as sparsity problems in contextual pre-filtering. This work involves the proposal of a method for the detection of the user contextual state when listening to music based on the social tags of music items. The intrinsic characteristics of social tagging that allow for the description of items in multiple dimensions can be exploited to capture many contextual dimensions in the user listening sessions. The embeddings of the tags of the first items played in each session are used to represent the context of that session. Recommendations are then generated based on both user preferences and the similarity of the items computed from tag embeddings. Social tags have been used extensively in many recommender systems, however, to our knowledge, they have been hardly used to dynamically infer contextual states.
Time-Aware Music Recommender Systems: Modeling the Evolution of Implicit User Preferences and User Listening Habits in A Collaborative Filtering Approach
Aug 26, 2020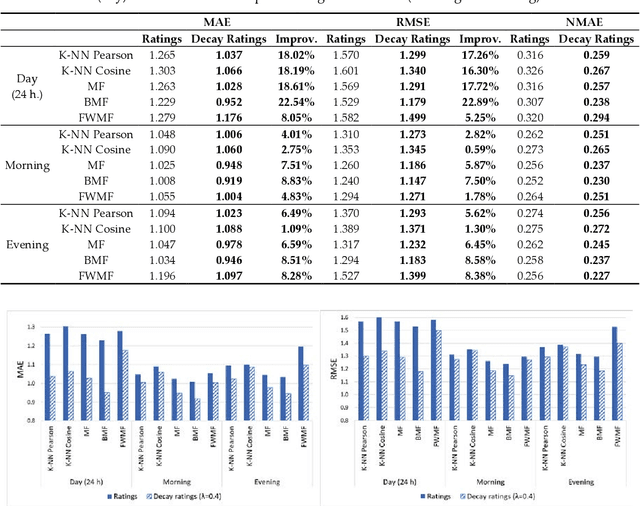
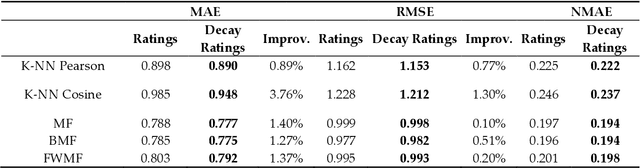
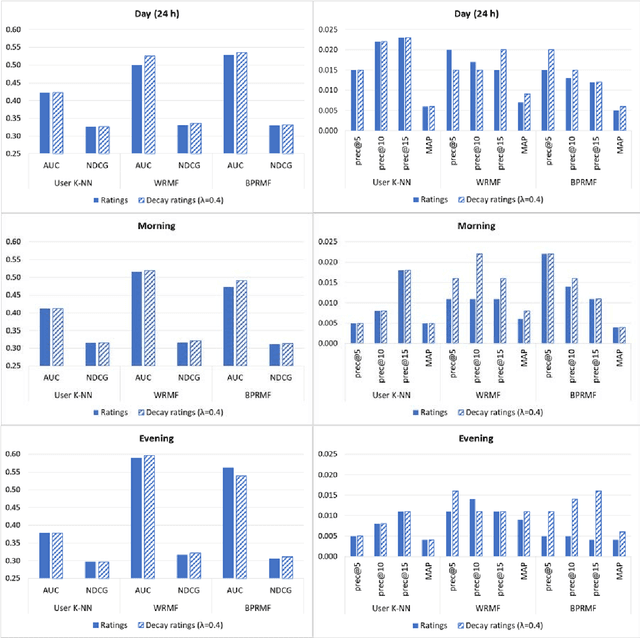
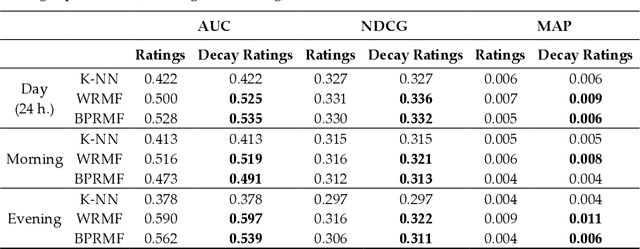
Online streaming services have become the most popular way of listening to music. The majority of these services are endowed with recommendation mechanisms that help users to discover songs and artists that may interest them from the vast amount of music available. However, many are not reliable as they may not take into account contextual aspects or the ever-evolving user behavior. Therefore, it is necessary to develop systems that consider these aspects. In the field of music, time is one of the most important factors influencing user preferences and managing its effects, and is the motivation behind the work presented in this paper. Here, the temporal information regarding when songs are played is examined. The purpose is to model both the evolution of user preferences in the form of evolving implicit ratings and user listening behavior. In the collaborative filtering method proposed in this work, daily listening habits are captured in order to characterize users and provide them with more reliable recommendations. The results of the validation prove that this approach outperforms other methods in generating both context-aware and context-free recommendations
Sentiment Analysis Based on Deep Learning: A Comparative Study
Jun 05, 2020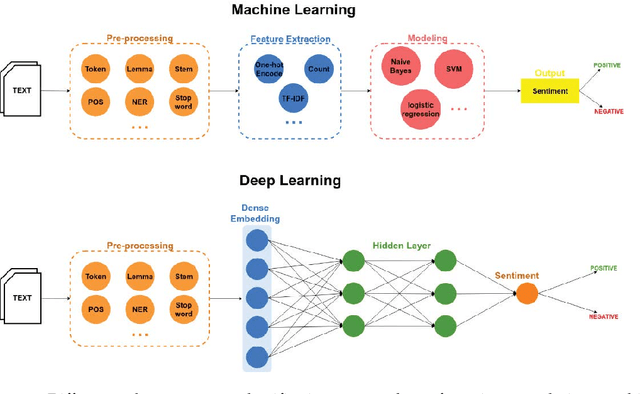

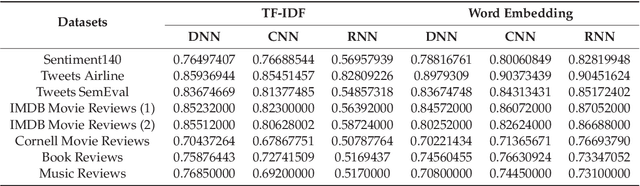

The study of public opinion can provide us with valuable information. The analysis of sentiment on social networks, such as Twitter or Facebook, has become a powerful means of learning about the users' opinions and has a wide range of applications. However, the efficiency and accuracy of sentiment analysis is being hindered by the challenges encountered in natural language processing (NLP). In recent years, it has been demonstrated that deep learning models are a promising solution to the challenges of NLP. This paper reviews the latest studies that have employed deep learning to solve sentiment analysis problems, such as sentiment polarity. Models using term frequency-inverse document frequency (TF-IDF) and word embedding have been applied to a series of datasets. Finally, a comparative study has been conducted on the experimental results obtained for the different models and input features
Predictive Modeling of ICU Healthcare-Associated Infections from Imbalanced Data. Using Ensembles and a Clustering-Based Undersampling Approach
May 07, 2020

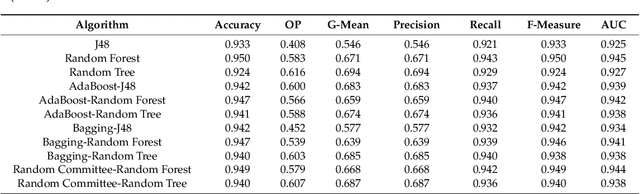
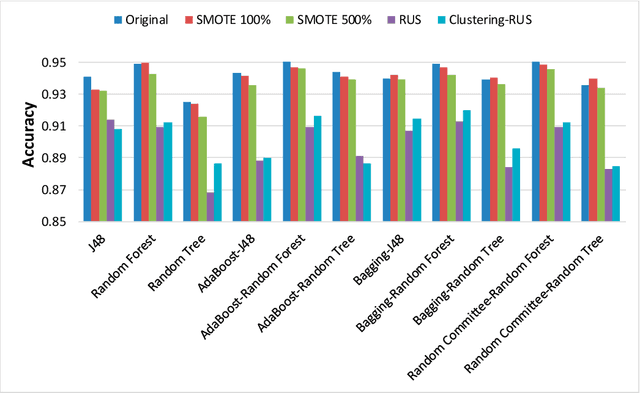
Early detection of patients vulnerable to infections acquired in the hospital environment is a challenge in current health systems given the impact that such infections have on patient mortality and healthcare costs. This work is focused on both the identification of risk factors and the prediction of healthcare-associated infections in intensive-care units by means of machine-learning methods. The aim is to support decision making addressed at reducing the incidence rate of infections. In this field, it is necessary to deal with the problem of building reliable classifiers from imbalanced datasets. We propose a clustering-based undersampling strategy to be used in combination with ensemble classifiers. A comparative study with data from 4616 patients was conducted in order to validate our proposal. We applied several single and ensemble classifiers both to the original dataset and to data preprocessed by means of different resampling methods. The results were analyzed by means of classic and recent metrics specifically designed for imbalanced data classification. They revealed that the proposal is more efficient in comparison with other approaches.
A session-based song recommendation approach involving user characterization along the play power-law distribution
Apr 25, 2020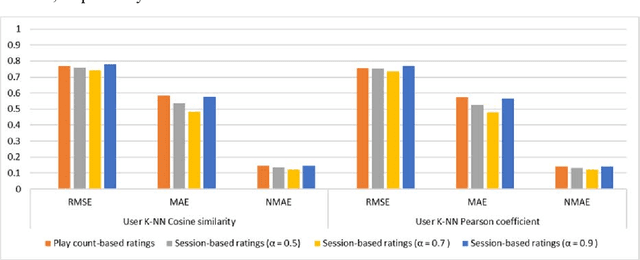
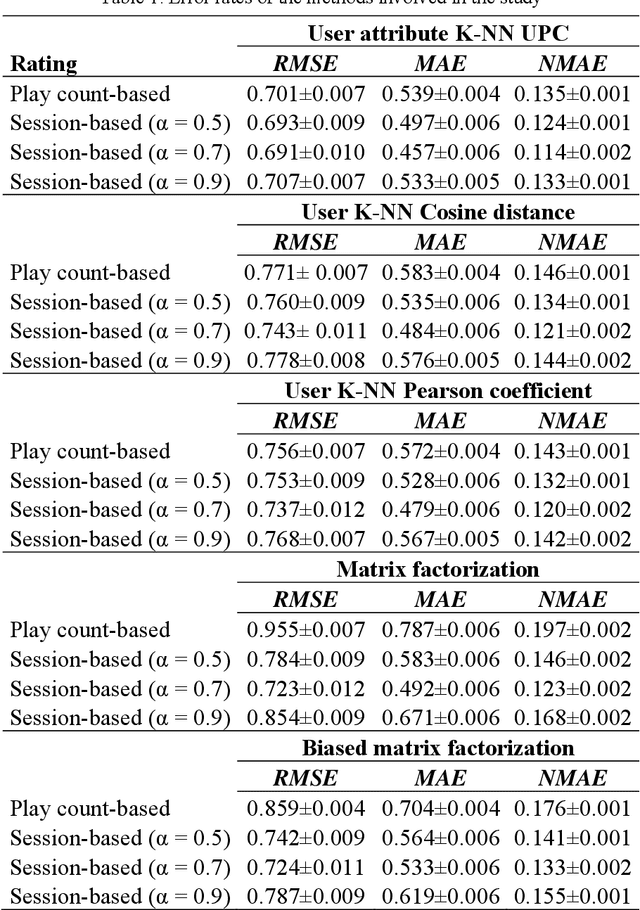
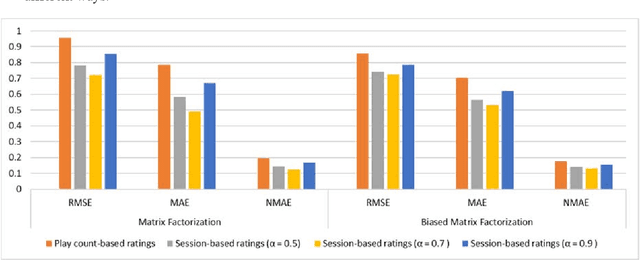
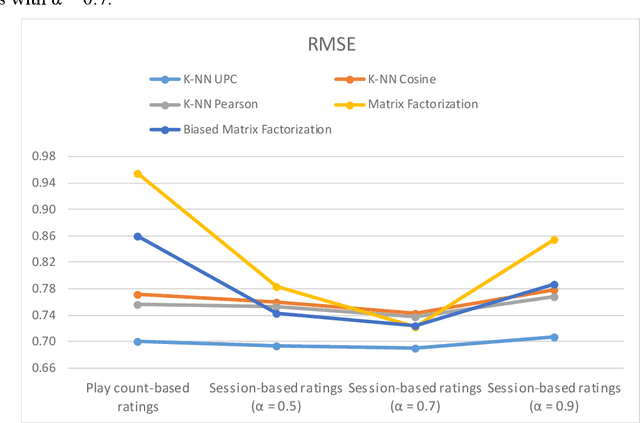
In recent years, streaming music platforms have become very popular mainly due to the huge number of songs these systems make available to users. This enormous availability means that recommendation mechanisms that help users to select the music they like need to be incorporated. However, developing reliable recommender systems in the music field involves dealing with many problems, some of which are generic and widely studied in the literature, while others are specific to this application domain and are therefore less well-known. This work is focused on two important issues that have not received much attention: managing gray-sheep users and obtaining implicit ratings. The first one is usually addressed by resorting to content information that is often difficult to obtain. The other drawback is related to the sparsity problem that arises when there are obstacles to gather explicit ratings. In this work, the referred shortcomings are addressed by means of a recommendation approach based on the users' streaming sessions. The method is aimed at managing the well-known power-law probability distribution representing the listening behavior of users. This proposal improves the recommendation reliability of collaborative filtering methods while reducing the complexity of the procedures used so far to deal with the gray-sheep problem.