 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDT-DCSCN for Simultaneous Super-Resolution and Deblurring of Text Images
Jan 15, 2022Deep convolutional neural networks (Deep CNN) have achieved hopeful performance for single image super-resolution. In particular, the Deep CNN skip Connection and Network in Network (DCSCN) architecture has been successfully applied to natural images super-resolution. In this work we propose an approach called SDT-DCSCN that jointly performs super-resolution and deblurring of low-resolution blurry text images based on DCSCN. Our approach uses subsampled blurry images in the input and original sharp images as ground truth. The used architecture is consists of a higher number of filters in the input CNN layer to a better analysis of the text details. The quantitative and qualitative evaluation on different datasets prove the high performance of our model to reconstruct high-resolution and sharp text images. In addition, in terms of computational time, our proposed method gives competitive performance compared to state of the art methods.
DELP-DAR System for License Plate Detection and Recognition
Oct 04, 2019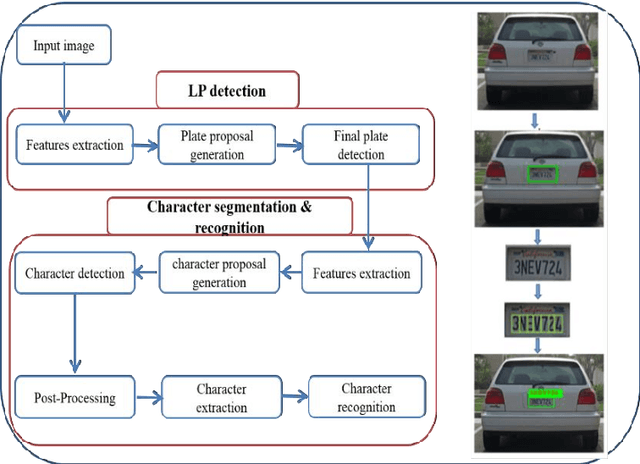
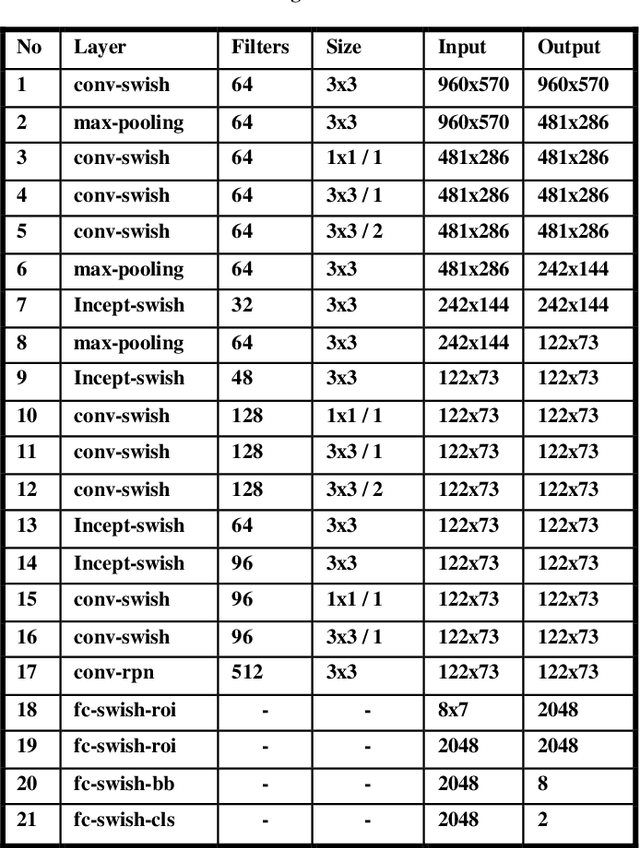
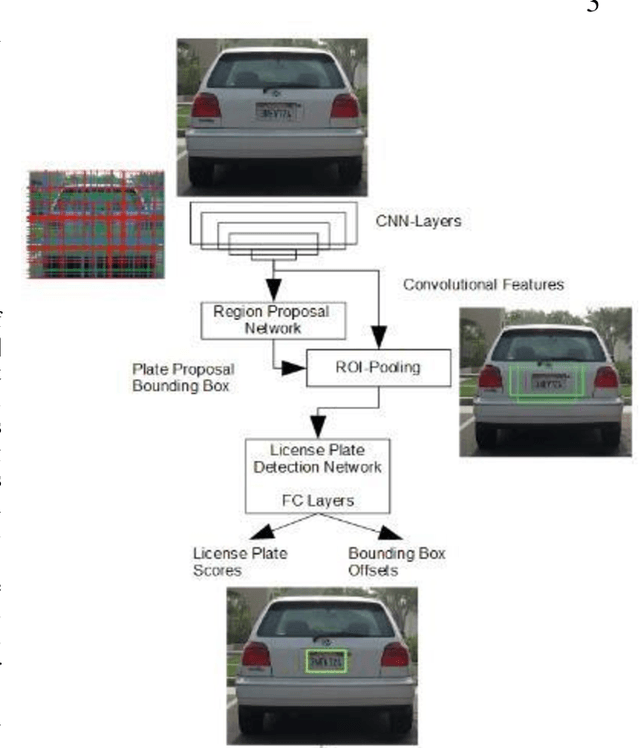
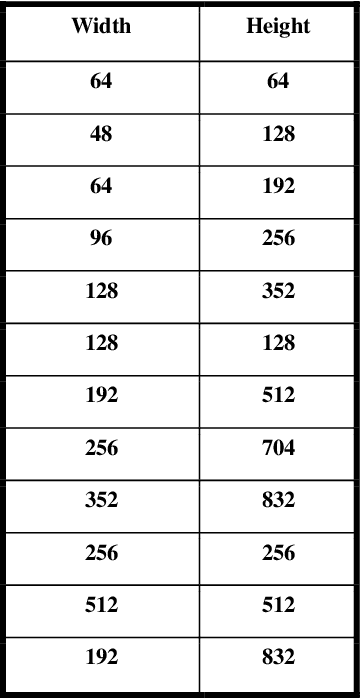
Automatic License Plate detection and Recognition (ALPR) is a quite popular and active research topic in the field of computer vision, image processing and intelligent transport systems. ALPR is used to make detection and recognition processes more robust and efficient in highly complicated environments and backgrounds. Several research investigations are still necessary due to some constraints such as: completeness of numbering systems of countries, different colors, various languages, multiple sizes and varied fonts. For this, we present in this paper an automatic framework for License Plate (LP) detection and recognition from complex scenes. Our framework is based on mask region convolutional neural networks used for LP detection, segmentation and recognition. Although some studies have focused on LP detection, LP recognition, LP segmentation or just two of them, our study uses the maskr-cnn in the three stages. The evaluation of our framework is enhanced by four datasets for different countries and consequently with various languages. In fact, it tested on four datasets including images captured from multiple scenes under numerous conditions such as varied orientation, poor quality images, blurred images and complex environmental backgrounds. Extensive experiments show the robustness and efficiency of our suggested framework in all datasets.
NF-SAVO: Neuro-Fuzzy system for Arabic Video OCR
Nov 09, 2012
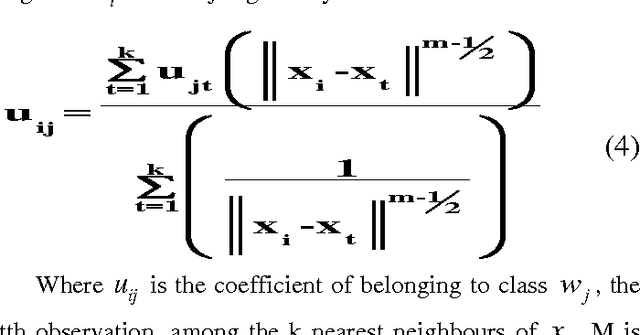
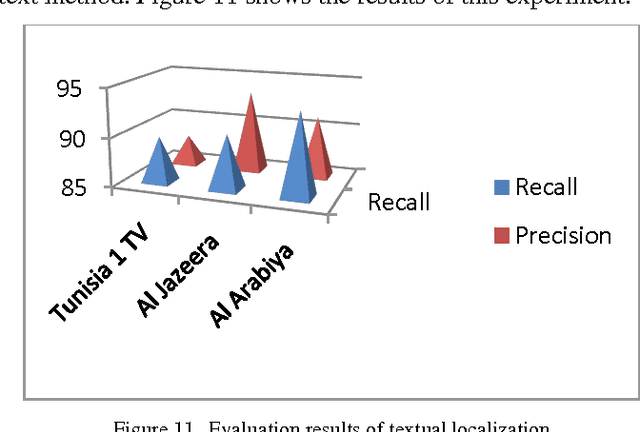
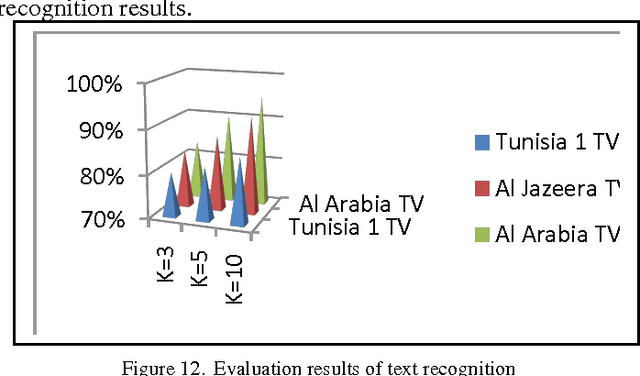
In this paper we propose a robust approach for text extraction and recognition from video clips which is called Neuro-Fuzzy system for Arabic Video OCR. In Arabic video text recognition, a number of noise components provide the text relatively more complicated to separate from the background. Further, the characters can be moving or presented in a diversity of colors, sizes and fonts that are not uniform. Added to this, is the fact that the background is usually moving making text extraction a more intricate process. Video include two kinds of text, scene text and artificial text. Scene text is usually text that becomes part of the scene itself as it is recorded at the time of filming the scene. But artificial text is produced separately and away from the scene and is laid over it at a later stage or during the post processing time. The emergence of artificial text is consequently vigilantly directed. This type of text carries with it important information that helps in video referencing, indexing and retrieval.
* 09 pages