 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Memetic Feature Selection Algorithm
Jan 26, 2016
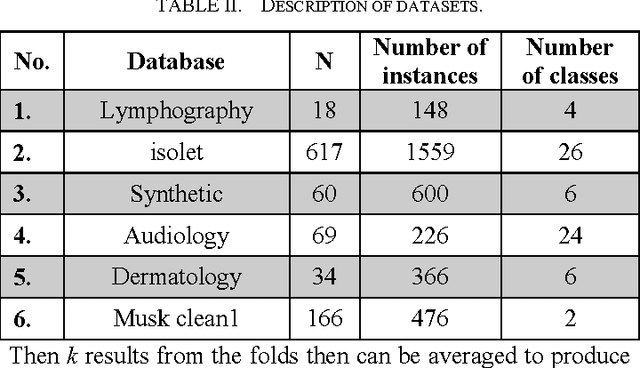
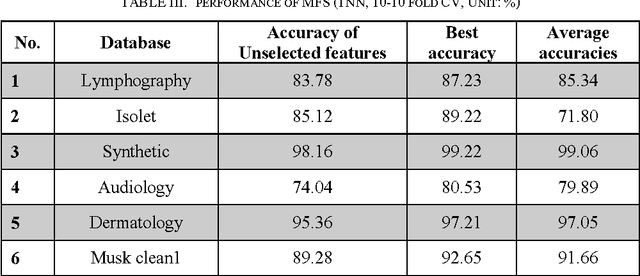
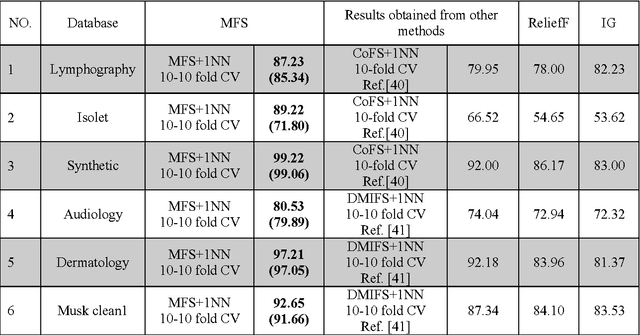
Feature selection is a problem of finding efficient features among all features in which the final feature set can improve accuracy and reduce complexity. In feature selection algorithms search strategies are key aspects. Since feature selection is an NP-Hard problem; therefore heuristic algorithms have been studied to solve this problem. In this paper, we have proposed a method based on memetic algorithm to find an efficient feature subset for a classification problem. It incorporates a filter method in the genetic algorithm to improve classification performance and accelerates the search in identifying core feature subsets. Particularly, the method adds or deletes a feature from a candidate feature subset based on the multivariate feature information. Empirical study on commonly data sets of the university of California, Irvine shows that the proposed method outperforms existing methods.
Hyper-Heuristic Algorithm for Finding Efficient Features in Diagnose of Lung Cancer Disease
Jan 24, 2016


Background: Lung cancer was known as primary cancers and the survival rate of cancer is about 15%. Early detection of lung cancer is the leading factor in survival rate. All symptoms (features) of lung cancer do not appear until the cancer spreads to other areas. It needs an accurate early detection of lung cancer, for increasing the survival rate. For accurate detection, it need characterizes efficient features and delete redundancy features among all features. Feature selection is the problem of selecting informative features among all features. Materials and Methods: Lung cancer database consist of 32 patient records with 57 features. This database collected by Hong and Youngand indexed in the University of California Irvine repository. Experimental contents include the extracted from the clinical data and X-ray data, etc. The data described 3 types of pathological lung cancers and all features are taking an integer value 0-3. In our study, new method is proposed for identify efficient features of lung cancer. It is based on Hyper-Heuristic. Results: We obtained an accuracy of 80.63% using reduced 11 feature set. The proposed method compare to the accuracy of 5 machine learning feature selections. The accuracy of these 5 methods are 60.94, 57.81, 68.75, 60.94 and 68.75. Conclusions: The proposed method has better performance with the highest level of accuracy. Therefore, the proposed model is recommended for identifying an efficient symptom of Disease. These finding are very important in health research, particularly in allocation of medical resources for patients who predicted as high-risks
* Published in the Journal of Basic and Applied Scientific Research, 2013
Eye detection in digital images: challenges and solutions
Jan 24, 2016Eye Detection has an important role in the field of biometric identification and known as one method of person's identification. In recent years, many efforts have been done which can detect eye automatically and with different image conditions. However, each method has its own drawbacks which can control some of these conditions. In this paper, different methods of eye detection will be categorized and explained. In each category, the advantages and disadvantages of each method will be presented.
Selecting Efficient Features via a Hyper-Heuristic Approach
Jan 20, 2016By Emerging huge databases and the need to efficient learning algorithms on these datasets, new problems have appeared and some methods have been proposed to solve these problems by selecting efficient features. Feature selection is a problem of finding efficient features among all features in which the final feature set can improve accuracy and reduce complexity. One way to solve this problem is to evaluate all possible feature subsets. However, evaluating all possible feature subsets is an exhaustive search and thus it has high computational complexity. Until now many heuristic algorithms have been studied for solving this problem. Hyper-heuristic is a new heuristic approach which can search the solution space effectively by applying local searches appropriately. Each local search is a neighborhood searching algorithm. Since each region of the solution space can have its own characteristics, it should be chosen an appropriate local search and apply it to current solution. This task is tackled to a supervisor. The supervisor chooses a local search based on the functional history of local searches. By doing this task, it can trade of between exploitation and exploration. Since the existing heuristic cannot trade of between exploration and exploitation appropriately, the solution space has not been searched appropriately in these methods and thus they have low convergence rate. For the first time, in this paper use a hyper-heuristic approach to find an efficient feature subset. In the proposed method, genetic algorithm is used as a supervisor and 16 heuristic algorithms are used as local searches. Empirical study of the proposed method on several commonly used data sets from UCI data sets indicates that it outperforms recent existing methods in the literature for feature selection.