 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Signal Mixing Aggregation for Message Passing Graph Neural Networks
Sep 28, 2024
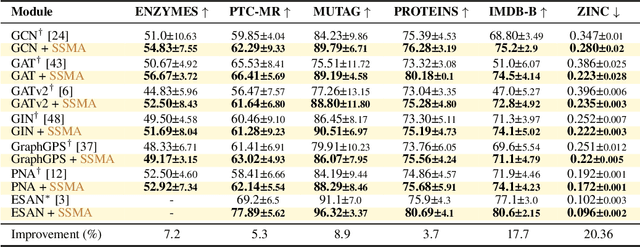


Message Passing Graph Neural Networks (MPGNNs) have emerged as the preferred method for modeling complex interactions across diverse graph entities. While the theory of such models is well understood, their aggregation module has not received sufficient attention. Sum-based aggregators have solid theoretical foundations regarding their separation capabilities. However, practitioners often prefer using more complex aggregations and mixtures of diverse aggregations. In this work, we unveil a possible explanation for this gap. We claim that sum-based aggregators fail to "mix" features belonging to distinct neighbors, preventing them from succeeding at downstream tasks. To this end, we introduce Sequential Signal Mixing Aggregation (SSMA), a novel plug-and-play aggregation for MPGNNs. SSMA treats the neighbor features as 2D discrete signals and sequentially convolves them, inherently enhancing the ability to mix features attributed to distinct neighbors. By performing extensive experiments, we show that when combining SSMA with well-established MPGNN architectures, we achieve substantial performance gains across various benchmarks, achieving new state-of-the-art results in many settings. We published our code at \url{https://almogdavid.github.io/SSMA/}
Enhanced Meta Label Correction for Coping with Label Corruption
May 22, 2023



Traditional methods for learning with the presence of noisy labels have successfully handled datasets with artificially injected noise but still fall short of adequately handling real-world noise. With the increasing use of meta-learning in the diverse fields of machine learning, researchers leveraged auxiliary small clean datasets to meta-correct the training labels. Nonetheless, existing meta-label correction approaches are not fully exploiting their potential. In this study, we propose an Enhanced Meta Label Correction approach abbreviated as EMLC for the learning with noisy labels (LNL) problem. We re-examine the meta-learning process and introduce faster and more accurate meta-gradient derivations. We propose a novel teacher architecture tailored explicitly to the LNL problem, equipped with novel training objectives. EMLC outperforms prior approaches and achieves state-of-the-art results in all standard benchmarks. Notably, EMLC enhances the previous art on the noisy real-world dataset Clothing1M by $1.52\%$ while requiring $\times 0.5$ the time per epoch and with much faster convergence of the meta-objective when compared to the baseline approach.