 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for Guiding LLMs to Use Software Design Patterns: A Case of Singleton
May 26, 2026Large Language Models (LLMs) can generate functional source code from natural-language prompts, but often fail to consistently follow higher-level architectural structures or design patterns. Since LLMs are increasingly used in software engineering, their ability to apply established design principles to generated code is crucial to the long-term success of software products. Therefore, the goal of this paper is to identify strategies for guiding LLMs to incorporate design patterns into the generated source code. We designed a computational experiment to evaluate the ability of 13 LLMs to generate code that follows the Singleton design pattern, using four prompting strategies: instructions, binary automated feedback, extensive automated feedback, and extensive feedback with few-shot prompts, in 164 Java coding challenges from HumanEval-X. Our results shows that the optimal strategy to guide LLMs to include design patterns depends heavily on the type of model. Still, overall, iterative binary feedback provides the best alignment with Singleton while preserving or improving the code's functionality. With guiding with instructions, Llama 3.3 generated Singleton classes in 100% of cases and improved code functionality, increasing the number of tests passed by 34.1 percentage points. It achieved a similar result with guidance through instructions and binary feedback. Qwen 3 (8B) increased the alignment with Singleton to 99.2% and the functionality to 58.6% using binary feedback. Our result suggests that even simple strategies can be used to guide LLMs to use design patterns.
Understanding Conversational Patterns in Multi-agent Programming: A Case Study on Fibonacci Game Development
May 22, 2026Large Language Models (LLMs) are increasingly applied to software engineering (SE), yet their potential for autonomous, role-oriented collaboration remains largely underexplored. Understanding how multiple LLM-based agents coordinate, maintain role alignment, and converge on solutions is critical for SE, as naively allowing agents to interact does not reliably lead to correct or stable outcomes. Recent empirical studies show that unstructured or poorly understood interaction dynamics can result in error propagation, premature consensus on incorrect solutions, or prolonged disagreement that prevents convergence, even when correct partial solutions are present early in the interaction. As an initial step towards addressing this underexplored area, we undertake a systematic analysis of conversations between two agents, a Designer and a Programmer across 12 model combinations from 7 open-source LLMs (Gemma 2, Gemma 3, LLaMA 3.2, LLaMA 3.3, DeepSeek-R1, MiniCPM, and Qwen3). Our systematic approach reveals three key dimensions of multi-agent interaction: efficiency (the speed and stability of convergence), consistency (the degree of role alignment visualized by BLEU and ROUGE), and effectiveness (the extent of compilation success and error resolution). Results show that the DeepSeek-R1:DeepSeek-R1 pair was unique in converging to the correct solution from the very first iteration and sustaining it consistently to the final iteration, while LLaMA 3.2:LLaMA 3.2 and Qwen3:Qwen3 demonstrated strong Designer:Programmer role alignment despite of diverging from the correct solution. The other pairs deviated from the task, never to converge to a result. These findings advance understanding of agentic programming and highlight the need for further research on understanding and calibrating convergence and stop conditions essential for future autonomous SE.
Data Leakage in Automotive Perception: Practitioners' Insights
Apr 08, 2026Data leakage is the inadvertent transfer of information between training and evaluation datasets that poses a subtle, yet critical, risk to the reliability of machine learning (ML) models in safety-critical systems such as automotive perception. While leakage is widely recognized in research, little is known about how industrial practitioners actually perceive and manage it in practice. This study investigates practitioners' knowledge, experiences, and mitigation strategies around data leakage through ten semi-structured interviews with system design, development, and verification engineers working on automotive perception functions development. Using reflexive thematic analysis, we identify that knowledge of data leakage is widespread and fragmented along role boundaries: ML engineers conceptualize it as a data-splitting or validation issue, whereas design and verification roles interpret it in terms of representativeness and scenario coverage. Detection commonly arises through generic considerations and observed performance anomalies rather than implying specific tools. However, data leakage prevention is more commonly practiced, which depends mostly on experience and knowledge sharing. These findings suggest that leakage control is a socio-technical coordination problem distributed across roles and workflows. We discuss implications for ML reliability engineering, highlighting the need for shared definitions, traceable data practices, and continuous cross-role communication to institutionalize data leakage awareness within automotive ML development.
Improving Image Data Leakage Detection in Automotive Software
Oct 29, 2024
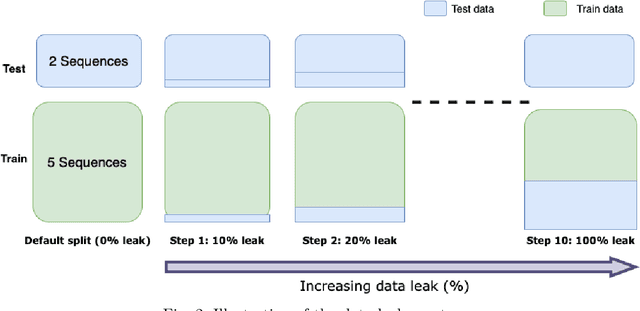
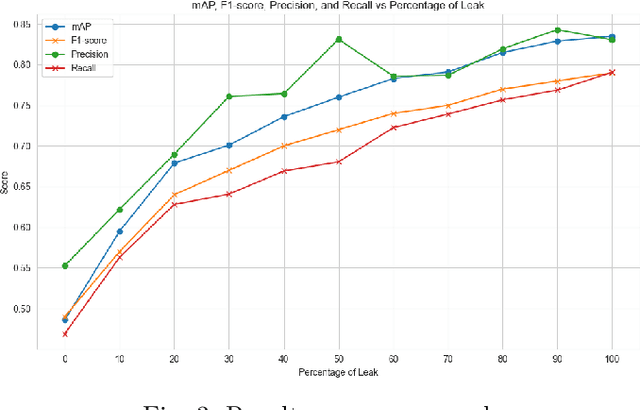
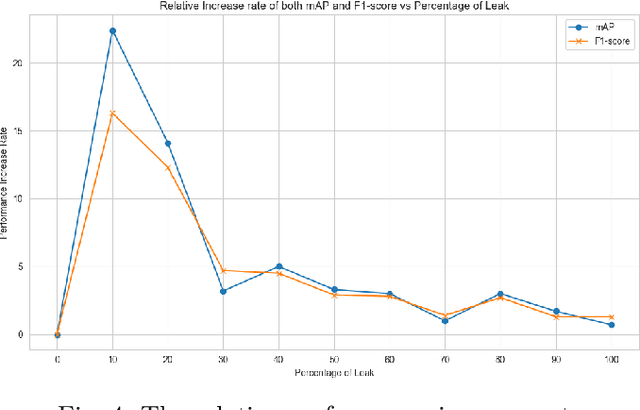
Data leakage is a very common problem that is often overlooked during splitting data into train and test sets before training any ML/DL model. The model performance gets artificially inflated with the presence of data leakage during the evaluation phase which often leads the model to erroneous prediction on real-time deployment. However, detecting the presence of such leakage is challenging, particularly in the object detection context of perception systems where the model needs to be supplied with image data for training. In this study, we conduct a computational experiment on the Cirrus dataset from our industrial partner Volvo Cars to develop a method for detecting data leakage. We then evaluate the method on another public dataset, Kitti, which is a popular and widely accepted benchmark dataset in the automotive domain. The results show that thanks to our proposed method we are able to detect data leakage in the Kitti dataset, which was previously unknown.
A Multi-model Approach for Video Data Retrieval in Autonomous Vehicle Development
Oct 04, 2024Autonomous driving software generates enormous amounts of data every second, which software development organizations save for future analysis and testing in the form of logs. However, given the vast size of this data, locating specific scenarios within a collection of vehicle logs can be challenging. Writing the correct SQL queries to find these scenarios requires engineers to have a strong background in SQL and the specific databases in question, further complicating the search process. This paper presents and evaluates a pipeline that allows searching for specific scenarios in log collections using natural language descriptions instead of SQL. The generated descriptions were evaluated by engineers working with vehicle logs at the Zenseact on a scale from 1 to 5. Our approach achieved a mean score of 3.3, demonstrating the potential of using a multi-model architecture to improve the software development workflow. We also present an interface that can visualize the query process and visualize the results.
Trusting Machine Learning Results from Medical Procedures in the Operating Room
Jan 04, 2022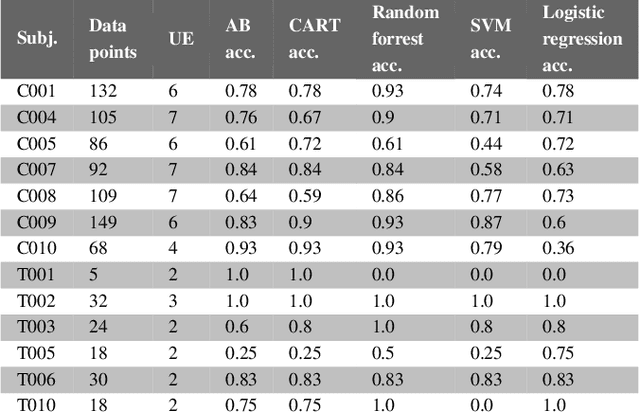
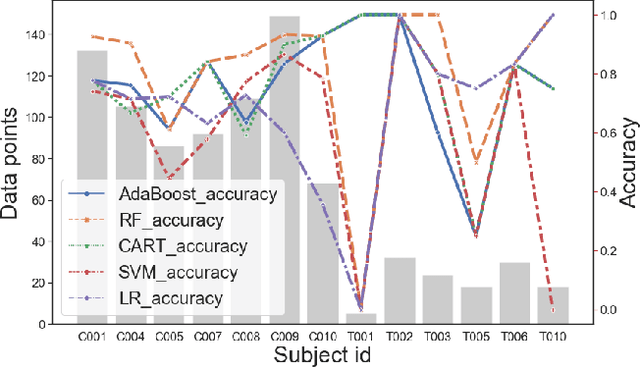
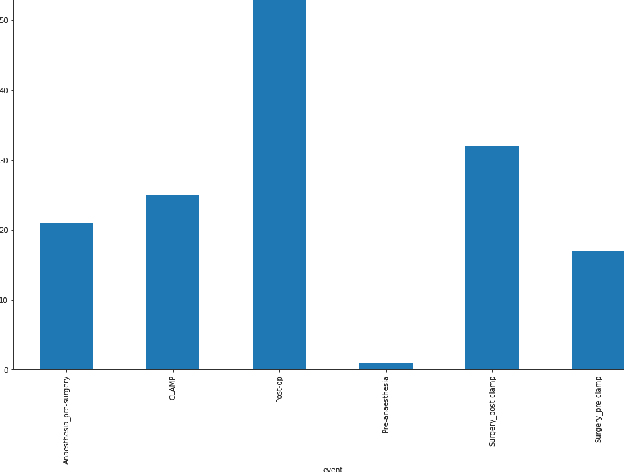
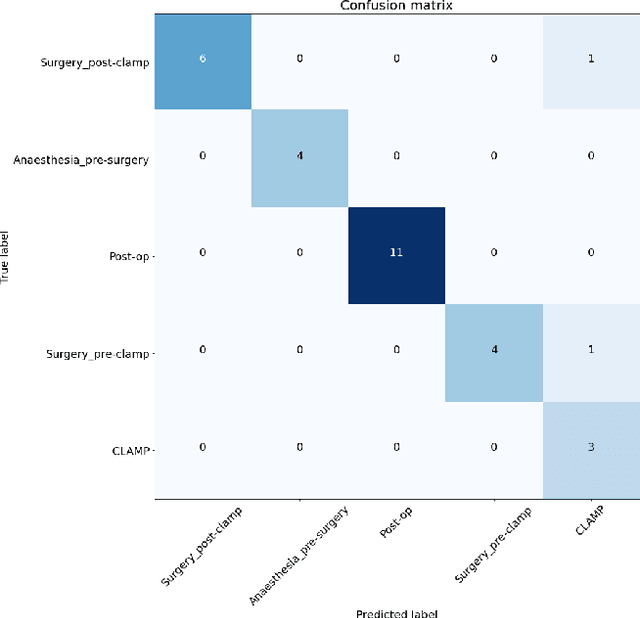
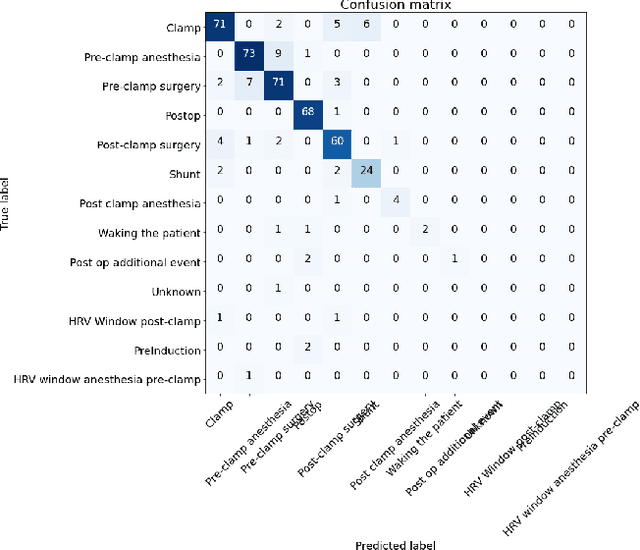
Machine learning can be used to analyse physiological data for several purposes. Detection of cerebral ischemia is an achievement that would have high impact on patient care. We attempted to study if collection of continous physiological data from non-invasive monitors, and analysis with machine learning could detect cerebral ischemia in tho different setting, during surgery for carotid endarterectomy and during endovascular thrombectomy in acute stroke. We compare the results from the two different group and one patient from each group in details. While results from CEA-patients are consistent, those from thrombectomy patients are not and frequently contain extreme values such as 1.0 in accuracy. We conlcude that this is a result of short duration of the procedure and abundance of data with bad quality resulting in small data sets. These results can therefore not be trusted.
Towards Trustworthy Cross-patient Model Development
Dec 20, 2021

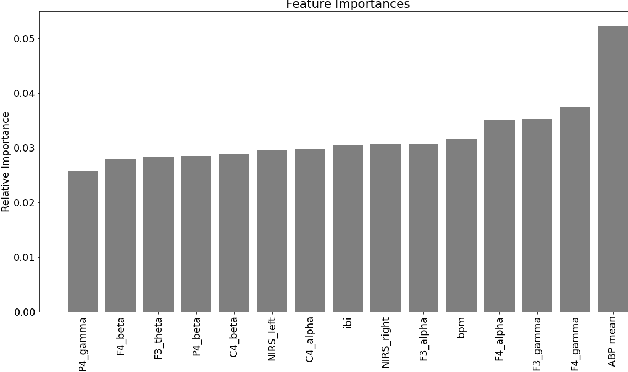
Machine learning is used in medicine to support physicians in examination, diagnosis, and predicting outcomes. One of the most dynamic area is the usage of patient generated health data from intensive care units. The goal of this paper is to demonstrate how we advance cross-patient ML model development by combining the patient's demographics data with their physiological data. We used a population of patients undergoing Carotid Enderarterectomy (CEA), where we studied differences in model performance and explainability when trained for all patients and one patient at a time. The results show that patients' demographics has a large impact on the performance and explainability and thus trustworthiness. We conclude that we can increase trust in ML models in a cross-patient context, by careful selection of models and patients based on their demographics and the surgical procedure.