 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Affine Transformation for Text-to-image Synthesis
Apr 22, 2022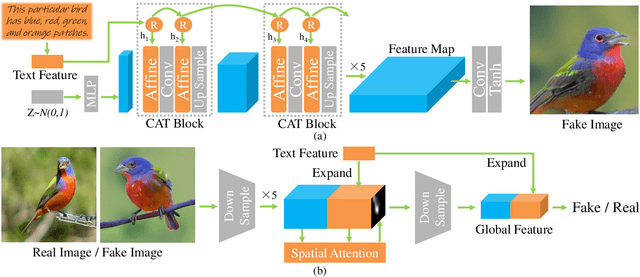
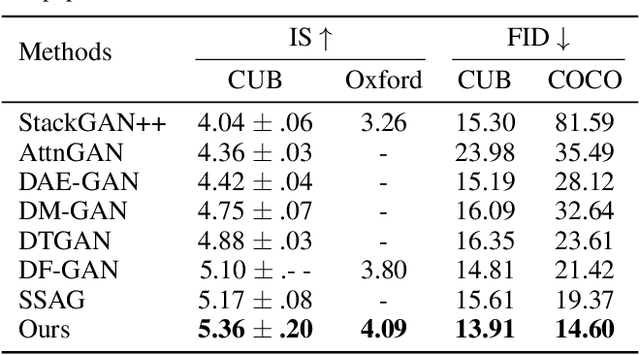

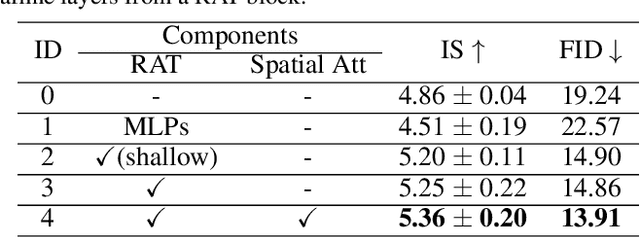
Text-to-image synthesis aims to generate natural images conditioned on text descriptions. The main difficulty of this task lies in effectively fusing text information into the image synthesis process. Existing methods usually adaptively fuse suitable text information into the synthesis process with multiple isolated fusion blocks (e.g., Conditional Batch Normalization and Instance Normalization). However, isolated fusion blocks not only conflict with each other but also increase the difficulty of training (see first page of the supplementary). To address these issues, we propose a Recurrent Affine Transformation (RAT) for Generative Adversarial Networks that connects all the fusion blocks with a recurrent neural network to model their long-term dependency. Besides, to improve semantic consistency between texts and synthesized images, we incorporate a spatial attention model in the discriminator. Being aware of matching image regions, text descriptions supervise the generator to synthesize more relevant image contents. Extensive experiments on the CUB, Oxford-102 and COCO datasets demonstrate the superiority of the proposed model in comparison to state-of-the-art models \footnote{https://github.com/senmaoy/Recurrent-Affine-Transformation-for-Text-to-image-Synthesis.git}