 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCAT: Cross-Attention Transformer for point cloud
Apr 06, 2023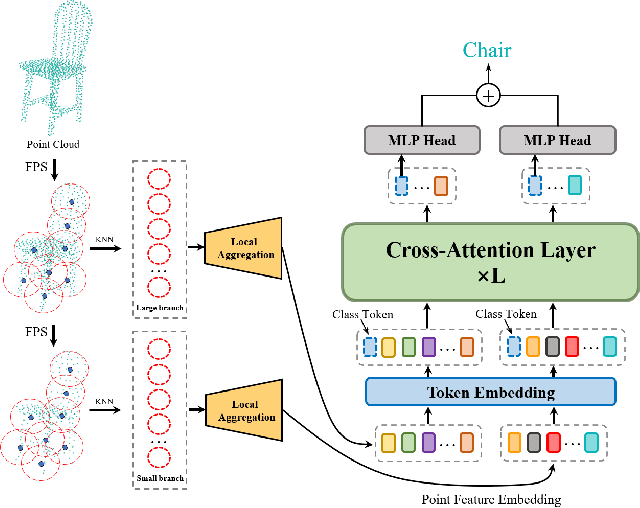

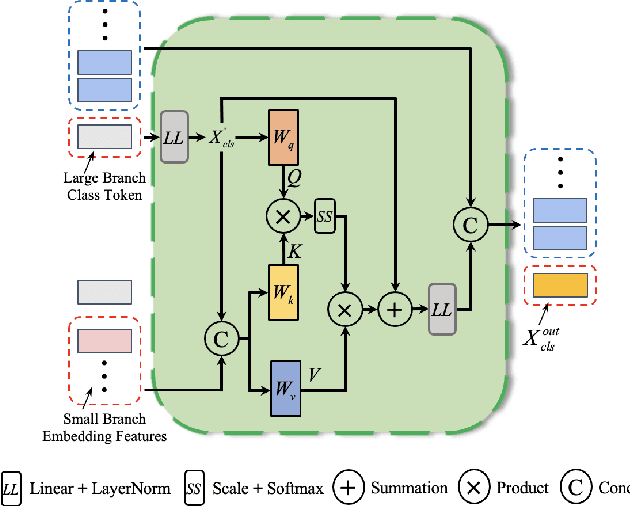

Transformer-based models have significantly advanced natural language processing and computer vision in recent years. However, due to the irregular and disordered structure of point cloud data, transformer-based models for 3D deep learning are still in their infancy compared to other methods. In this paper we present Point Cross-Attention Transformer (PointCAT), a novel end-to-end network architecture using cross-attentions mechanism for point cloud representing. Our approach combines multi-scale features via two seprate cross-attention transformer branches. To reduce the computational increase brought by multi-branch structure, we further introduce an efficient model for shape classification, which only process single class token of one branch as a query to calculate attention map with the other. Extensive experiments demonstrate that our method outperforms or achieves comparable performance to several approaches in shape classification, part segmentation and semantic segmentation tasks.