 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Robust Speaker Counting and Separation with the Aid of Spatial Coherence
Mar 13, 2023A two-stage approach is proposed for speaker counting and speech separation in noisy and reverberant environments. A spatial coherence matrix (SCM) is computed using whitened relative transfer functions (wRTFs) across time frames. The global activity functions of each speaker are estimated on the basis of a simplex constructed using the eigenvectors of the SCM, while the local coherence functions are computed from the coherence between the wRTFs of a time-frequency bin and the global activity function-weighted RTF of the target speaker. In speaker counting, we use the eigenvalues of the SCM and the maximum similarity of the interframe global activity distributions between two speakers as the input features to the speaker counting network (SCnet). In speaker separation, a global and local activity-driven network (GLADnet) is utilized to estimate a speaker mask, which is particularly useful for highly overlapping speech signals. Experimental results obtained from the real meeting recordings demonstrated the superior speaker counting and speaker separation performance achieved by the proposed learning-based system without prior knowledge of the array configurations.
Acoustic echo suppression using a learning-based multi-frame minimum variance distortionless response filter
May 07, 2022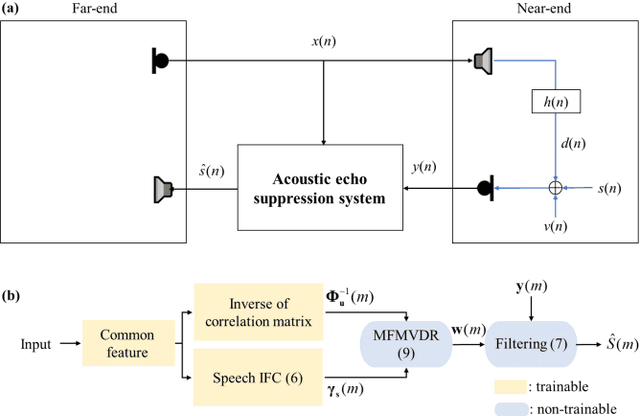
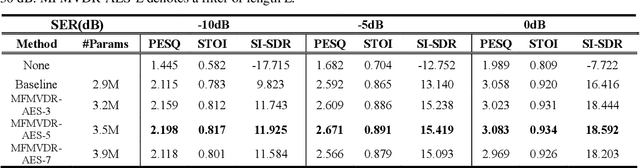
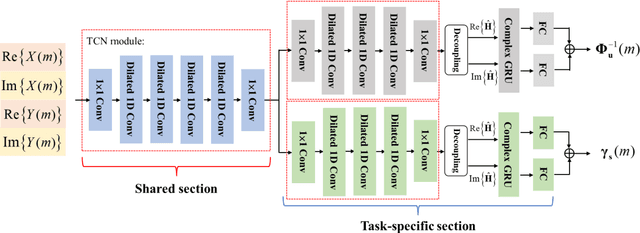
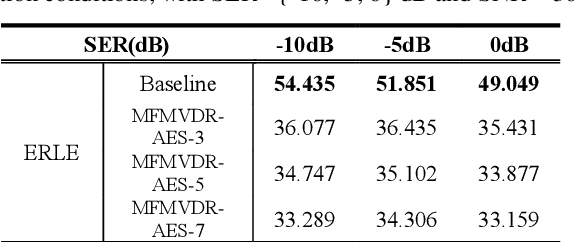
Distortion resulting from acoustic echo suppression (AES) is a common issue in full-duplex communication. To address the distortion problem, a multi-frame minimum variance distortionless response (MFMVDR) filtering technique is proposed. The MFMVDR filter with parameter estimation which was used in speech enhancement problems is extended in this study from a deep learning perspective. To alleviate numerical instability of the MFMVDR filter, we propose to directly estimate the inverse of the correlation matrix. The AES system is advantageous in that no double-talk detection is required. The negative scale-invariant signal-to-distortion ratio is employed as the loss function in training the network at the output of the MFMVDR filter. Simulation results have demonstrated the efficacy of the proposed learning-based AES system in double-talk, background noise, and nonlinear distortion conditions.