 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific QA System with Verifiable Answers
Jul 16, 2024


In this paper, we introduce the VerifAI project, a pioneering open-source scientific question-answering system, designed to provide answers that are not only referenced but also automatically vetted and verifiable. The components of the system are (1) an Information Retrieval system combining semantic and lexical search techniques over scientific papers (PubMed), (2) a Retrieval-Augmented Generation (RAG) module using fine-tuned generative model (Mistral 7B) and retrieved articles to generate claims with references to the articles from which it was derived, and (3) a Verification engine, based on a fine-tuned DeBERTa and XLM-RoBERTa models on Natural Language Inference task using SciFACT dataset. The verification engine cross-checks the generated claim and the article from which the claim was derived, verifying whether there may have been any hallucinations in generating the claim. By leveraging the Information Retrieval and RAG modules, Verif.ai excels in generating factual information from a vast array of scientific sources. At the same time, the Verification engine rigorously double-checks this output, ensuring its accuracy and reliability. This dual-stage process plays a crucial role in acquiring and confirming factual information, significantly enhancing the information landscape. Our methodology could significantly enhance scientists' productivity, concurrently fostering trust in applying generative language models within scientific domains, where hallucinations and misinformation are unacceptable.
How do you know that? Teaching Generative Language Models to Reference Answers to Biomedical Questions
Jul 06, 2024



Large language models (LLMs) have recently become the leading source of answers for users' questions online. Despite their ability to offer eloquent answers, their accuracy and reliability can pose a significant challenge. This is especially true for sensitive domains such as biomedicine, where there is a higher need for factually correct answers. This paper introduces a biomedical retrieval-augmented generation (RAG) system designed to enhance the reliability of generated responses. The system is based on a fine-tuned LLM for the referenced question-answering, where retrieved relevant abstracts from PubMed are passed to LLM's context as input through a prompt. Its output is an answer based on PubMed abstracts, where each statement is referenced accordingly, allowing the users to verify the answer. Our retrieval system achieves an absolute improvement of 23% compared to the PubMed search engine. Based on the manual evaluation on a small sample, our fine-tuned LLM component achieves comparable results to GPT-4 Turbo in referencing relevant abstracts. We make the dataset used to fine-tune the models and the fine-tuned models based on Mistral-7B-instruct-v0.1 and v0.2 publicly available.
A transformer-based method for zero and few-shot biomedical named entity recognition
May 12, 2023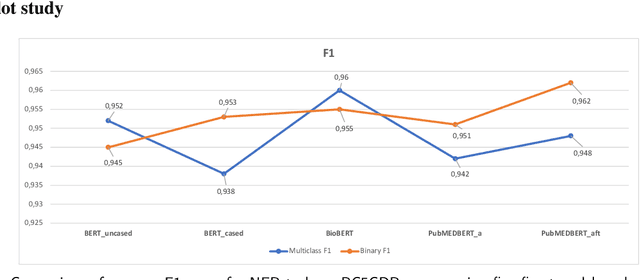
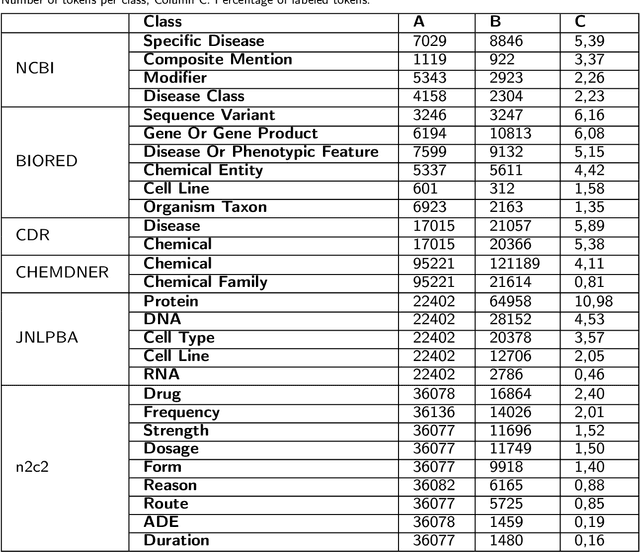

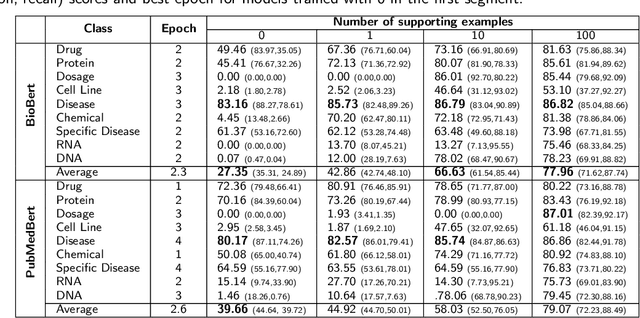
Supervised named entity recognition (NER) in the biomedical domain is dependent on large sets of annotated texts with the given named entities, whose creation can be time-consuming and expensive. Furthermore, the extraction of new entities often requires conducting additional annotation tasks and retraining the model. To address these challenges, this paper proposes a transformer-based method for zero- and few-shot NER in the biomedical domain. The method is based on transforming the task of multi-class token classification into binary token classification (token contains the searched entity or does not contain the searched entity) and pre-training on a larger amount of datasets and biomedical entities, from where the method can learn semantic relations between the given and potential classes. We have achieved average F1 scores of 35.44% for zero-shot NER, 50.10% for one-shot NER, 69.94% for 10-shot NER, and 79.51% for 100-shot NER on 9 diverse evaluated biomedical entities with PubMedBERT fine-tuned model. The results demonstrate the effectiveness of the proposed method for recognizing new entities with limited examples, with comparable or better results from the state-of-the-art zero- and few-shot NER methods.