 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Data-Production Dispositif
May 24, 2022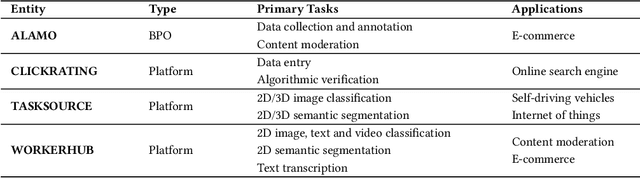
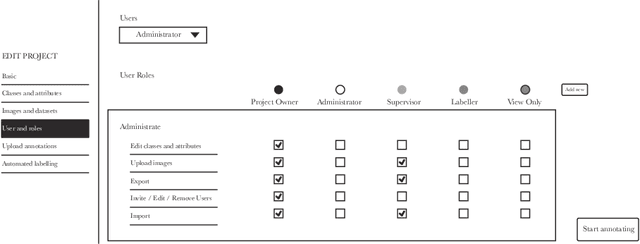
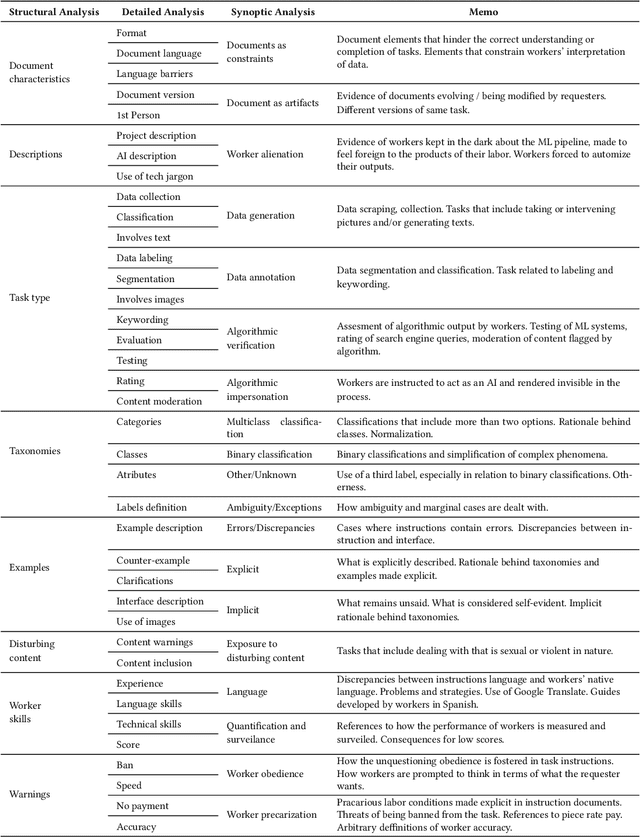
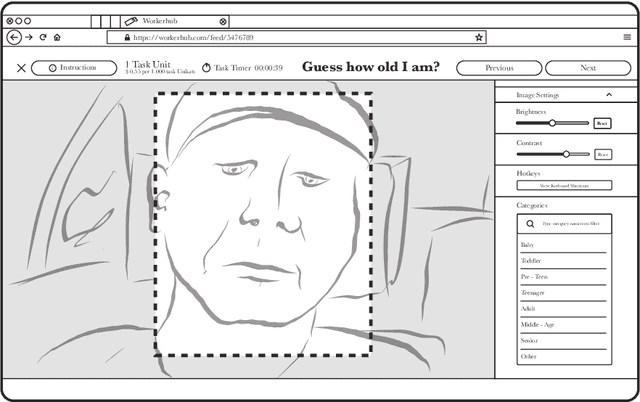
Machine learning (ML) depends on data to train and verify models. Very often, organizations outsource processes related to data work (i.e., generating and annotating data and evaluating outputs) through business process outsourcing (BPO) companies and crowdsourcing platforms. This paper investigates outsourced ML data work in Latin America by studying three platforms in Venezuela and a BPO in Argentina. We lean on the Foucauldian notion of dispositif to define the data-production dispositif as an ensemble of discourses, actions, and objects strategically disposed to (re)produce power/knowledge relations in data and labor. Our dispositif analysis comprises the examination of 210 data work instruction documents, 55 interviews with data workers, managers, and requesters, and participant observation. Our findings show that discourses encoded in instructions reproduce and normalize the worldviews of requesters. Precarious working conditions and economic dependency alienate workers, making them obedient to instructions. Furthermore, discourses and social contexts materialize in artifacts, such as interfaces and performance metrics, limiting workers' agency and normalizing specific ways of interpreting data. We conclude by stressing the importance of counteracting the data-production dispositif by fighting alienation and precarization, and empowering data workers to become assets in the quest for high-quality data.
Studying Up Machine Learning Data: Why Talk About Bias When We Mean Power?
Sep 16, 2021Research in machine learning (ML) has primarily argued that models trained on incomplete or biased datasets can lead to discriminatory outputs. In this commentary, we propose moving the research focus beyond bias-oriented framings by adopting a power-aware perspective to "study up" ML datasets. This means accounting for historical inequities, labor conditions, and epistemological standpoints inscribed in data. We draw on HCI and CSCW work to support our argument, critically analyze previous research, and point at two co-existing lines of work within our community -- one bias-oriented, the other power-aware. This way, we highlight the need for dialogue and cooperation in three areas: data quality, data work, and data documentation. In the first area, we argue that reducing societal problems to "bias" misses the context-based nature of data. In the second one, we highlight the corporate forces and market imperatives involved in the labor of data workers that subsequently shape ML datasets. Finally, we propose expanding current transparency-oriented efforts in dataset documentation to reflect the social contexts of data design and production.
Wisdom for the Crowd: Discoursive Power in Annotation Instructions for Computer Vision
May 23, 2021
Developers of computer vision algorithms outsource some of the labor involved in annotating training data through business process outsourcing companies and crowdsourcing platforms. Many data annotators are situated in the Global South and are considered independent contractors. This paper focuses on the experiences of Argentinian and Venezuelan annotation workers. Through qualitative methods, we explore the discourses encoded in the task instructions that these workers follow to annotate computer vision datasets. Our preliminary findings indicate that annotation instructions reflect worldviews imposed on workers and, through their labor, on datasets. Moreover, we observe that for-profit goals drive task instructions and that managers and algorithms make sure annotations are done according to requesters' commands. This configuration presents a form of commodified labor that perpetuates power asymmetries while reinforcing social inequalities and is compelled to reproduce them into datasets and, subsequently, in computer vision systems.
Between Subjectivity and Imposition: Power Dynamics in Data Annotation for Computer Vision
Jul 30, 2020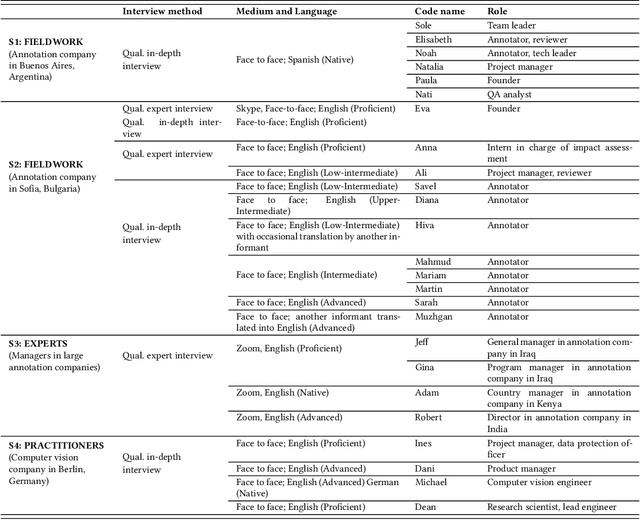
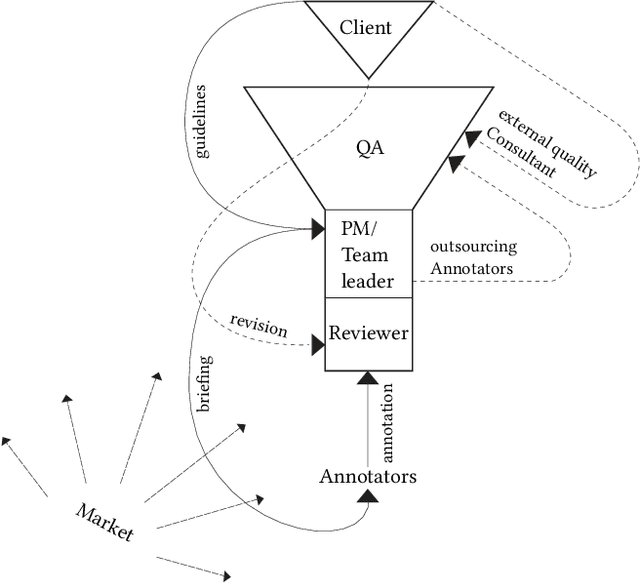
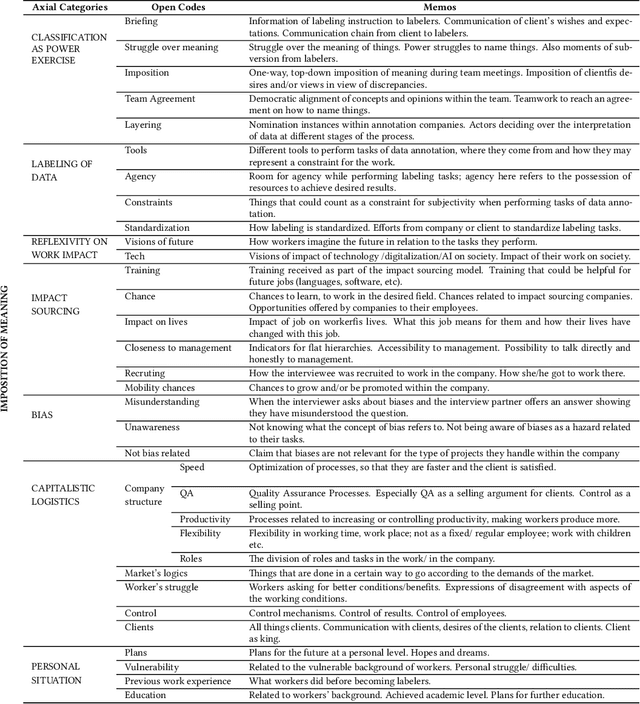
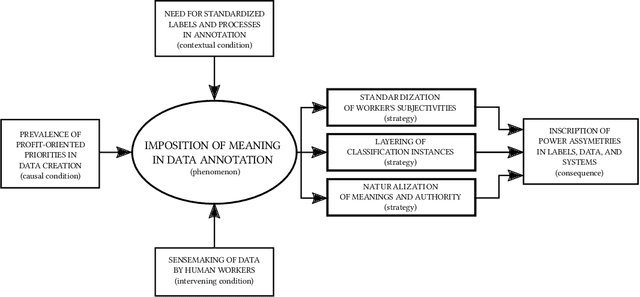
The interpretation of data is fundamental to machine learning. This paper investigates practices of image data annotation as performed in industrial contexts. We define data annotation as a sense-making practice, where annotators assign meaning to data through the use of labels. Previous human-centered investigations have largely focused on annotators subjectivity as a major cause for biased labels. We propose a wider view on this issue: guided by constructivist grounded theory, we conducted several weeks of fieldwork at two annotation companies. We analyzed which structures, power relations, and naturalized impositions shape the interpretation of data. Our results show that the work of annotators is profoundly informed by the interests, values, and priorities of other actors above their station. Arbitrary classifications are vertically imposed on annotators, and through them, on data. This imposition is largely naturalized. Assigning meaning to data is often presented as a technical matter. This paper shows it is, in fact, an exercise of power with multiple implications for individuals and society.