 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTookaBERT: A Step Forward for Persian NLU
Jul 23, 2024The field of natural language processing (NLP) has seen remarkable advancements, thanks to the power of deep learning and foundation models. Language models, and specifically BERT, have been key players in this progress. In this study, we trained and introduced two new BERT models using Persian data. We put our models to the test, comparing them to seven existing models across 14 diverse Persian natural language understanding (NLU) tasks. The results speak for themselves: our larger model outperforms the competition, showing an average improvement of at least +2.8 points. This highlights the effectiveness and potential of our new BERT models for Persian NLU tasks.
ViraPart: A Text Refinement Framework for ASR and NLP Tasks in Persian
Oct 19, 2021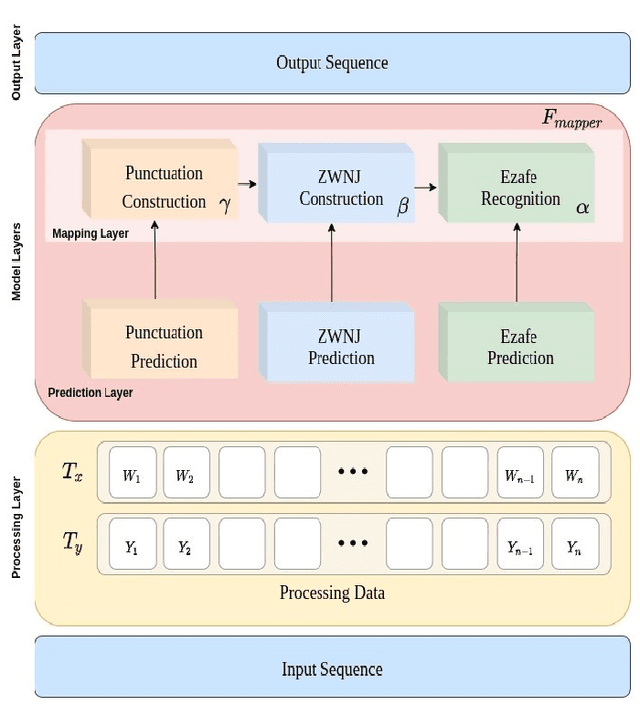
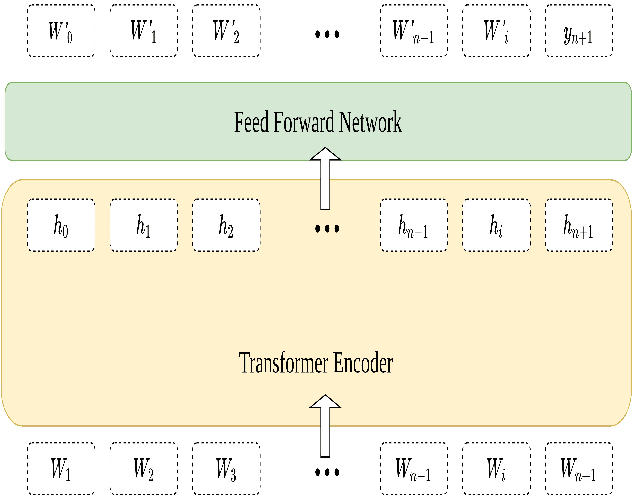

The Persian language is an inflectional SOV language. This fact makes Persian a more uncertain language. However, using techniques such as ZWNJ recognition, punctuation restoration, and Persian Ezafe construction will lead us to a more understandable and precise language. In most of the works in Persian, these techniques are addressed individually. Despite that, we believe that for text refinement in Persian, all of these tasks are necessary. In this work, we proposed a ViraPart framework that uses embedded ParsBERT in its core for text clarifications. First, used the BERT variant for Persian following by a classifier layer for classification procedures. Next, we combined models outputs to output cleartext. In the end, the proposed model for ZWNJ recognition, punctuation restoration, and Persian Ezafe construction performs the averaged F1 macro scores of 96.90%, 92.13%, and 98.50%, respectively. Experimental results show that our proposed approach is very effective in text refinement for the Persian language.