 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting gamma-band responses to the speech envelope for the ICASSP 2024 Auditory EEG Decoding Signal Processing Grand Challenge
Jan 30, 2024The 2024 ICASSP Auditory EEG Signal Processing Grand Challenge concerns the decoding of electroencephalography (EEG) measurements taken from participants who listened to speech material. This work details our solution to the match-mismatch sub-task: given a short temporal segment of EEG recordings and several candidate speech segments, the task is to classify which of the speech segments was time-aligned with the EEG signals. We show that high-frequency gamma-band responses to the speech envelope can be detected with a high accuracy. By jointly assessing gamma-band responses and low-frequency envelope tracking, we develop a match-mismatch decoder which placed first in this task.
Decoding of Selective Attention to Speech From Ear-EEG Recordings
Jan 10, 2024



Many people with hearing loss struggle to comprehend speech in crowded auditory scenes, even when they are using hearing aids. Future hearing technologies which can identify the focus of a listener's auditory attention, and selectively amplify that sound alone, could improve the experience that this patient group has with their hearing aids. In this work, we present the results of our experiments with an ultra-wearable in-ear electroencephalography (EEG) monitoring device. Participants listened to two competing speakers in an auditory attention experiment whilst their EEG was recorded. We show that typical neural responses to the speech envelope, as well as its onsets, can be recovered from such a device, and that the morphology of the recorded responses is indeed modulated by selective attention to speech. Features of the attended and ignored speech stream can also be reconstructed from the EEG recordings, with the reconstruction quality serving as a marker of selective auditory attention. Using the stimulus-reconstruction method, we show that with this device auditory attention can be decoded from short segments of EEG recordings which are of just a few seconds in duration. The results provide further evidence that ear-EEG systems offer good prospects for wearable auditory monitoring as well as future cognitively-steered hearing aids.
Decoding Envelope and Frequency-Following EEG Responses to Continuous Speech Using Deep Neural Networks
Dec 15, 2023


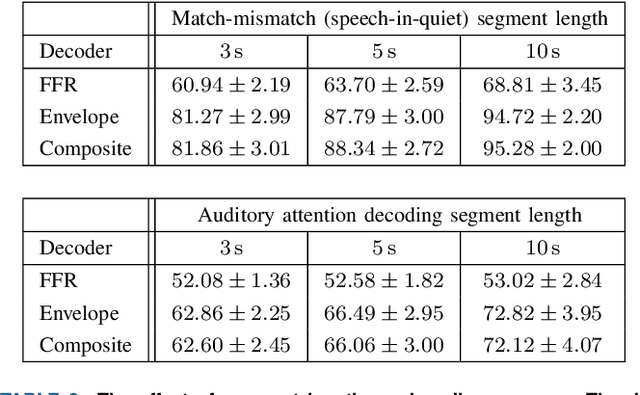
The electroencephalogram (EEG) offers a non-invasive means by which a listener's auditory system may be monitored during continuous speech perception. Reliable auditory-EEG decoders could facilitate the objective diagnosis of hearing disorders, or find applications in cognitively-steered hearing aids. Previously, we developed decoders for the ICASSP Auditory EEG Signal Processing Grand Challenge (SPGC). These decoders aimed to solve the match-mismatch task: given a short temporal segment of EEG recordings, and two candidate speech segments, the task is to identify which of the two speech segments is temporally aligned, or matched, with the EEG segment. The decoders made use of cortical responses to the speech envelope, as well as speech-related frequency-following responses, to relate the EEG recordings to the speech stimuli. Here we comprehensively document the methods by which the decoders were developed. We extend our previous analysis by exploring the association between speaker characteristics (pitch and sex) and classification accuracy, and provide a full statistical analysis of the final performance of the decoders as evaluated on a heldout portion of the dataset. Finally, the generalisation capabilities of the decoders are characterised, by evaluating them using an entirely different dataset which contains EEG recorded under a variety of speech-listening conditions. The results show that the match-mismatch decoders achieve accurate and robust classification accuracies, and they can even serve as auditory attention decoders without additional training.
Relating EEG recordings to speech using envelope tracking and the speech-FFR
Mar 11, 2023During speech perception, a listener's electroencephalogram (EEG) reflects acoustic-level processing as well as higher-level cognitive factors such as speech comprehension and attention. However, decoding speech from EEG recordings is challenging due to the low signal-to-noise ratios of EEG signals. We report on an approach developed for the ICASSP 2023 'Auditory EEG Decoding' Signal Processing Grand Challenge. A simple ensembling method is shown to considerably improve upon the baseline decoder performance. Even higher classification rates are achieved by jointly decoding the speech-evoked frequency-following response and responses to the temporal envelope of speech, as well as by fine-tuning the decoders to individual subjects. Our results could have applications in the diagnosis of hearing disorders or in cognitively steered hearing aids.