 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPAR: Unified Pedestrian Attribute Recognition and Person Retrieval
Sep 06, 2022

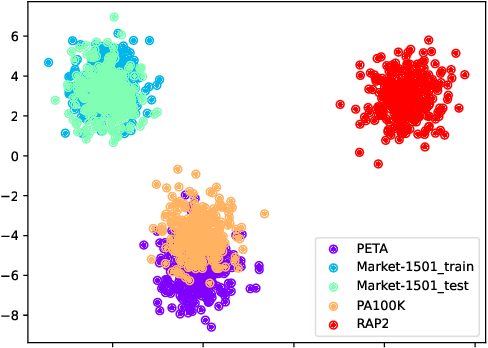
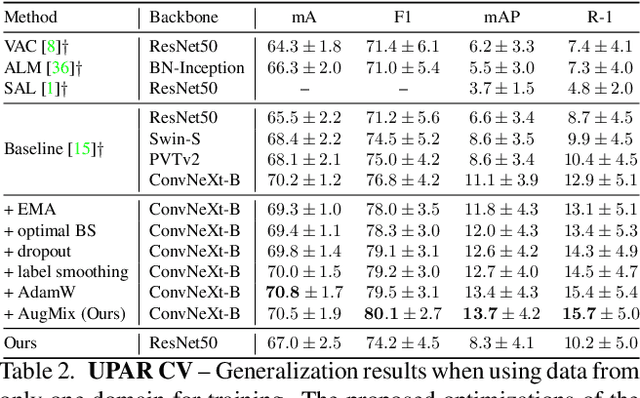
Recognizing soft-biometric pedestrian attributes is essential in video surveillance and fashion retrieval. Recent works show promising results on single datasets. Nevertheless, the generalization ability of these methods under different attribute distributions, viewpoints, varying illumination, and low resolutions remains rarely understood due to strong biases and varying attributes in current datasets. To close this gap and support a systematic investigation, we present UPAR, the Unified Person Attribute Recognition Dataset. It is based on four well-known person attribute recognition datasets: PA100K, PETA, RAPv2, and Market1501. We unify those datasets by providing 3,3M additional annotations to harmonize 40 important binary attributes over 12 attribute categories across the datasets. We thus enable research on generalizable pedestrian attribute recognition as well as attribute-based person retrieval for the first time. Due to the vast variance of the image distribution, pedestrian pose, scale, and occlusion, existing approaches are greatly challenged both in terms of accuracy and efficiency. Furthermore, we develop a strong baseline for PAR and attribute-based person retrieval based on a thorough analysis of regularization methods. Our models achieve state-of-the-art performance in cross-domain and specialization settings on PA100k, PETA, RAPv2, Market1501-Attributes, and UPAR. We believe UPAR and our strong baseline will contribute to the artificial intelligence community and promote research on large-scale, generalizable attribute recognition systems.
Do as we do: Multiple Person Video-To-Video Transfer
Apr 10, 2021



Our goal is to transfer the motion of real people from a source video to a target video with realistic results. While recent advances significantly improved image-to-image translations, only few works account for body motions and temporal consistency. However, those focus only on video re-targeting for a single actor/ for single actors. In this work, we propose a marker-less approach for multiple-person video-to-video transfer using pose as an intermediate representation. Given a source video with multiple persons dancing or working out, our method transfers the body motion of all actors to a new set of actors in a different video. Differently from recent "do as I do" methods, we focus specifically on transferring multiple person at the same time and tackle the related identity switch problem. Our method is able to convincingly transfer body motion to the target video, while preserving specific features of the target video, such as feet touching the floor and relative position of the actors. The evaluation is performed with visual quality and appearance metrics using publicly available videos with the permission of their owners.