 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual KokoroChat: A Multi-LLM Ensemble Translation Method for Creating a Multilingual Counseling Dialogue Dataset
Mar 24, 2026To address the critical scarcity of high-quality, publicly available counseling dialogue datasets, we created Multilingual KokoroChat by translating KokoroChat, a large-scale manually authored Japanese counseling corpus, into both English and Chinese. A key challenge in this process is that the optimal model for translation varies by input, making it impossible for any single model to consistently guarantee the highest quality. In a sensitive domain like counseling, where the highest possible translation fidelity is essential, relying on a single LLM is therefore insufficient. To overcome this challenge, we developed and employed a novel multi-LLM ensemble method. Our approach first generates diverse hypotheses from multiple distinct LLMs. A single LLM then produces a high-quality translation based on an analysis of the respective strengths and weaknesses of all presented hypotheses. The quality of ``Multilingual KokoroChat'' was rigorously validated through human preference studies. These evaluations confirmed that the translations produced by our ensemble method were preferred from any individual state-of-the-art LLM. This strong preference confirms the superior quality of our method's outputs. The Multilingual KokoroChat is available at https://github.com/UEC-InabaLab/MultilingualKokoroChat.
Refining Text Generation for Realistic Conversational Recommendation via Direct Preference Optimization
Aug 28, 2025Conversational Recommender Systems (CRSs) aim to elicit user preferences via natural dialogue to provide suitable item recommendations. However, current CRSs often deviate from realistic human interactions by rapidly recommending items in brief sessions. This work addresses this gap by leveraging Large Language Models (LLMs) to generate dialogue summaries from dialogue history and item recommendation information from item description. This approach enables the extraction of both explicit user statements and implicit preferences inferred from the dialogue context. We introduce a method using Direct Preference Optimization (DPO) to ensure dialogue summary and item recommendation information are rich in information crucial for effective recommendations. Experiments on two public datasets validate our method's effectiveness in fostering more natural and realistic conversational recommendation processes.Our implementation is publicly available at: https://github.com/UEC-InabaLab/Refining-LLM-Text
EmoStage: A Framework for Accurate Empathetic Response Generation via Perspective-Taking and Phase Recognition
Jun 24, 2025The rising demand for mental health care has fueled interest in AI-driven counseling systems. While large language models (LLMs) offer significant potential, current approaches face challenges, including limited understanding of clients' psychological states and counseling stages, reliance on high-quality training data, and privacy concerns associated with commercial deployment. To address these issues, we propose EmoStage, a framework that enhances empathetic response generation by leveraging the inference capabilities of open-source LLMs without additional training data. Our framework introduces perspective-taking to infer clients' psychological states and support needs, enabling the generation of emotionally resonant responses. In addition, phase recognition is incorporated to ensure alignment with the counseling process and to prevent contextually inappropriate or inopportune responses. Experiments conducted in both Japanese and Chinese counseling settings demonstrate that EmoStage improves the quality of responses generated by base models and performs competitively with data-driven methods.
Enhancing Dialogue Generation in Werewolf Game Through Situation Analysis and Persuasion Strategies
Sep 04, 2024Recent advancements in natural language processing, particularly with large language models (LLMs) like GPT-4, have significantly enhanced dialogue systems, enabling them to generate more natural and fluent conversations. Despite these improvements, challenges persist, such as managing continuous dialogues, memory retention, and minimizing hallucinations. The AIWolfDial2024 addresses these challenges by employing the Werewolf Game, an incomplete information game, to test the capabilities of LLMs in complex interactive environments. This paper introduces a LLM-based Werewolf Game AI, where each role is supported by situation analysis to aid response generation. Additionally, for the werewolf role, various persuasion strategies, including logical appeal, credibility appeal, and emotional appeal, are employed to effectively persuade other players to align with its actions.
Data Augmentation Integrating Dialogue Flow and Style to Adapt Spoken Dialogue Systems to Low-Resource User Groups
Aug 20, 2024This study addresses the interaction challenges encountered by spoken dialogue systems (SDSs) when engaging with users who exhibit distinct conversational behaviors, particularly minors, in scenarios where data are scarce. We propose a novel data augmentation framework to enhance SDS performance for user groups with limited resources. Our approach leverages a large language model (LLM) to extract speaker styles and a pre-trained language model (PLM) to simulate dialogue act history. This method generates enriched and personalized dialogue data, facilitating improved interactions with unique user demographics. Extensive experiments validate the efficacy of our methodology, highlighting its potential to foster the development of more adaptive and inclusive dialogue systems.
Can Large Language Models be Used to Provide Psychological Counselling? An Analysis of GPT-4-Generated Responses Using Role-play Dialogues
Feb 20, 2024

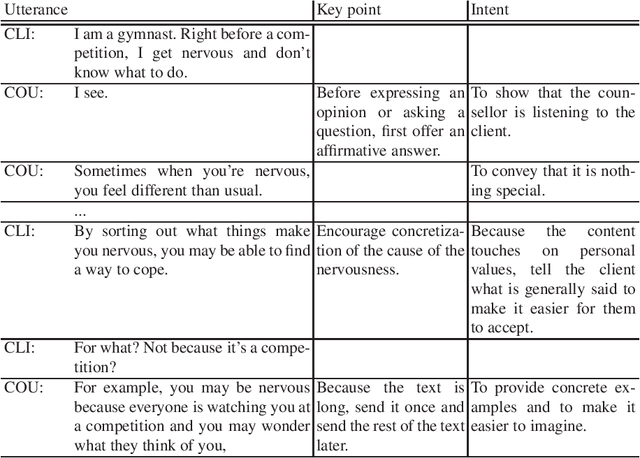

Mental health care poses an increasingly serious challenge to modern societies. In this context, there has been a surge in research that utilizes information technologies to address mental health problems, including those aiming to develop counseling dialogue systems. However, there is a need for more evaluations of the performance of counseling dialogue systems that use large language models. For this study, we collected counseling dialogue data via role-playing scenarios involving expert counselors, and the utterances were annotated with the intentions of the counselors. To determine the feasibility of a dialogue system in real-world counseling scenarios, third-party counselors evaluated the appropriateness of responses from human counselors and those generated by GPT-4 in identical contexts in role-play dialogue data. Analysis of the evaluation results showed that the responses generated by GPT-4 were competitive with those of human counselors.
SumRec: A Framework for Recommendation using Open-Domain Dialogue
Feb 07, 2024Chat dialogues contain considerable useful information about a speaker's interests, preferences, and experiences.Thus, knowledge from open-domain chat dialogue can be used to personalize various systems and offer recommendations for advanced information.This study proposed a novel framework SumRec for recommending information from open-domain chat dialogue.The study also examined the framework using ChatRec, a newly constructed dataset for training and evaluation. To extract the speaker and item characteristics, the SumRec framework employs a large language model (LLM) to generate a summary of the speaker information from a dialogue and to recommend information about an item according to the type of user.The speaker and item information are then input into a score estimation model, generating a recommendation score.Experimental results show that the SumRec framework provides better recommendations than the baseline method of using dialogues and item descriptions in their original form. Our dataset and code is publicly available at https://github.com/Ryutaro-A/SumRec
Enhancing Consistency in Multimodal Dialogue System Using LLM with Dialogue Scenario
Dec 20, 2023This paper describes our dialogue system submitted to Dialogue Robot Competition 2023. The system's task is to help a user at a travel agency decide on a plan for visiting two sightseeing spots in Kyoto City that satisfy the user. Our dialogue system is flexible and stable and responds to user requirements by controlling dialogue flow according to dialogue scenarios. We also improved user satisfaction by introducing motion and speech control based on system utterances and user situations. In the preliminary round, our system was ranked fifth in the impression evaluation and sixth in the plan evaluation among all 12 teams.