 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Comparison Feedback: Online Estimation of Sample Statistics
Jan 11, 2021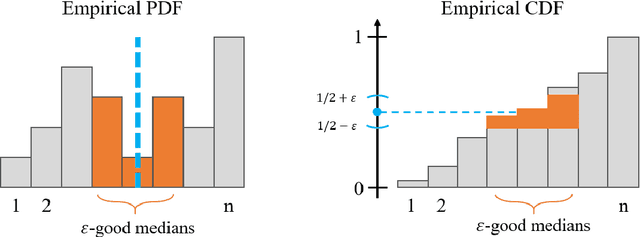
We study an online version of the noisy binary search problem where feedback is generated by a non-stochastic adversary rather than perturbed by random noise. We reframe this as maintaining an accurate estimate for the median of an adversarial sequence of integers, $x_1, x_2, \dots$, in a model where each number $x_t$ can only be accessed through a single threshold query of the form ${1(x_t \leq q_t)}$. In this online comparison feedback model, we explore estimation of general sample statistics, providing robust algorithms for median, CDF, and mean estimation with nearly matching lower bounds. We conclude with several high-dimensional generalizations.
A Data Prism: Semi-Verified Learning in the Small-Alpha Regime
Aug 09, 2017We consider a model of unreliable or crowdsourced data where there is an underlying set of $n$ binary variables, each evaluator contributes a (possibly unreliable or adversarial) estimate of the values of some subset of $r$ of the variables, and the learner is given the true value of a constant number of variables. We show that, provided an $\alpha$-fraction of the evaluators are "good" (either correct, or with independent noise rate $p < 1/2$), then the true values of a $(1-\epsilon)$ fraction of the $n$ underlying variables can be deduced as long as $\alpha > 1/(2-2p)^r$. This setting can be viewed as an instance of the semi-verified learning model introduced in [CSV17], which explores the tradeoff between the number of items evaluated by each worker and the fraction of good evaluators. Our results require the number of evaluators to be extremely large, $>n^r$, although our algorithm runs in linear time, $O_{r,\epsilon}(n)$, given query access to the large dataset of evaluations. This setting and results can also be viewed as examining a general class of semi-adversarial CSPs with a planted assignment. This parameter regime where the fraction of reliable data is small, is relevant to a number of practical settings. For example, settings where one has a large dataset of customer preferences, with each customer specifying preferences for a small (constant) number of items, and the goal is to ascertain the preferences of a specific demographic of interest. Our results show that this large dataset (which lacks demographic information) can be leveraged together with the preferences of the demographic of interest for a constant number of randomly selected items, to recover an accurate estimate of the entire set of preferences. In this sense, our results can be viewed as a "data prism" allowing one to extract the behavior of specific cohorts from a large, mixed, dataset.