 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Function Approximation in Zero-Sum Markov Games
Dec 12, 2012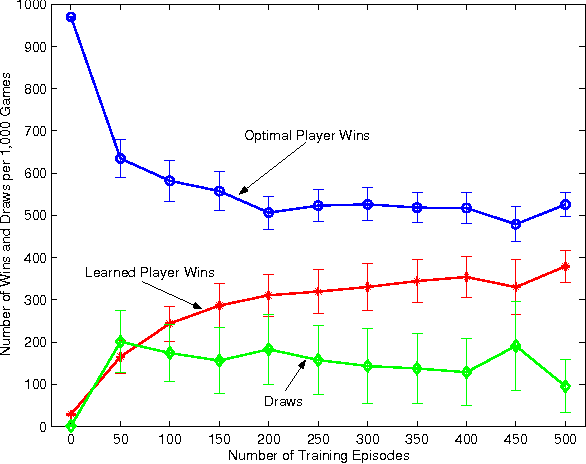
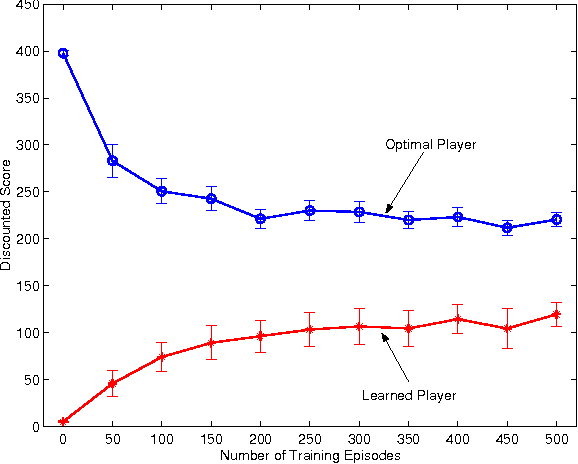
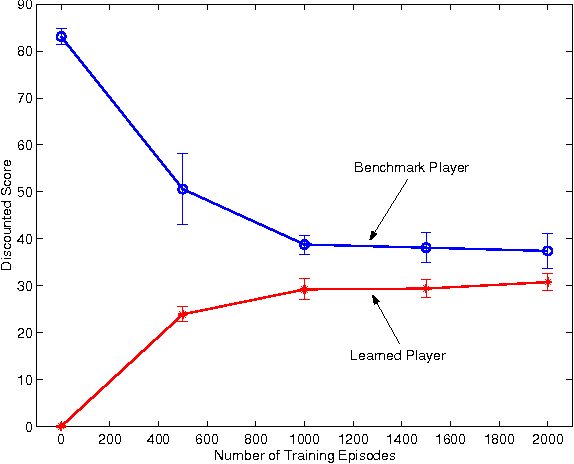
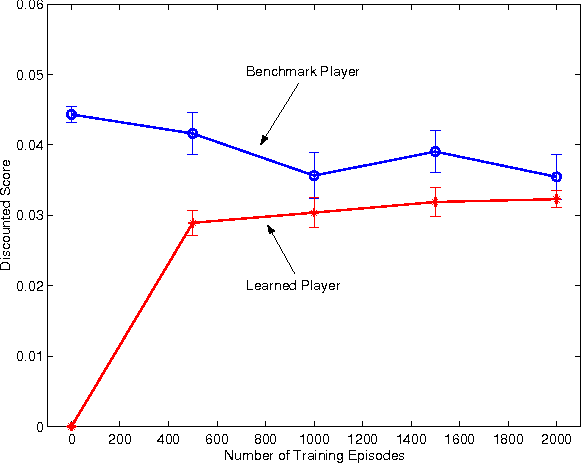
This paper investigates value function approximation in the context of zero-sum Markov games, which can be viewed as a generalization of the Markov decision process (MDP) framework to the two-agent case. We generalize error bounds from MDPs to Markov games and describe generalizations of reinforcement learning algorithms to Markov games. We present a generalization of the optimal stopping problem to a two-player simultaneous move Markov game. For this special problem, we provide stronger bounds and can guarantee convergence for LSTD and temporal difference learning with linear value function approximation. We demonstrate the viability of value function approximation for Markov games by using the Least squares policy iteration (LSPI) algorithm to learn good policies for a soccer domain and a flow control problem.