 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalization Result for Convergence in Learning-to-Optimize
Oct 10, 2024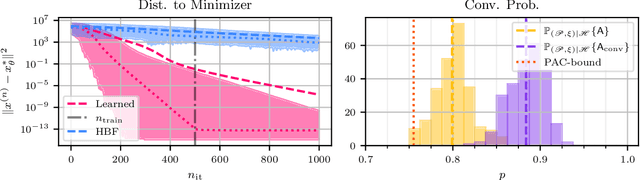

Convergence in learning-to-optimize is hardly studied, because conventional convergence guarantees in optimization are based on geometric arguments, which cannot be applied easily to learned algorithms. Thus, we develop a probabilistic framework that resembles deterministic optimization and allows for transferring geometric arguments into learning-to-optimize. Our main theorem is a generalization result for parametric classes of potentially non-smooth, non-convex loss functions and establishes the convergence of learned optimization algorithms to stationary points with high probability. This can be seen as a statistical counterpart to the use of geometric safeguards to ensure convergence. To the best of our knowledge, we are the first to prove convergence of optimization algorithms in such a probabilistic framework.
A Markovian Model for Learning-to-Optimize
Aug 21, 2024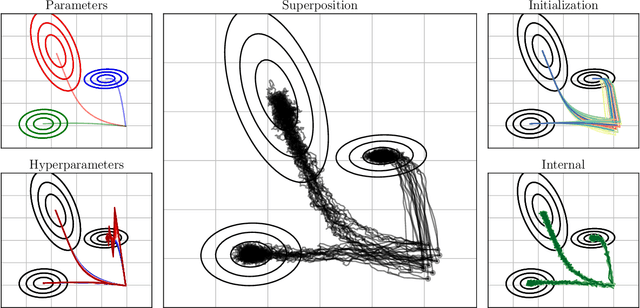
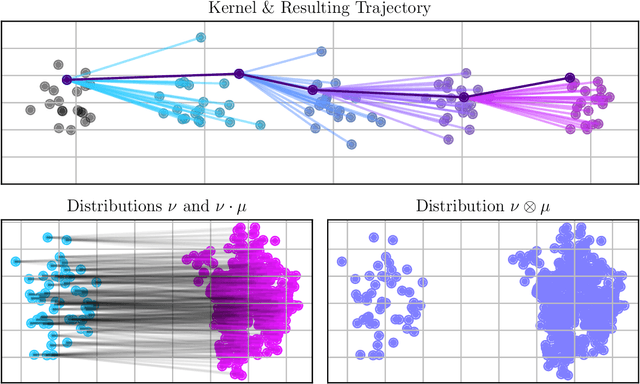
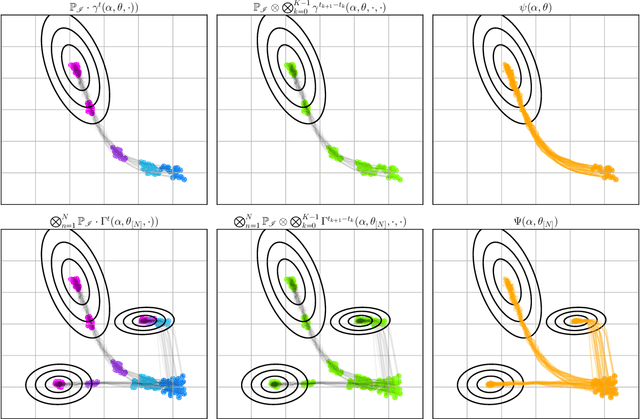

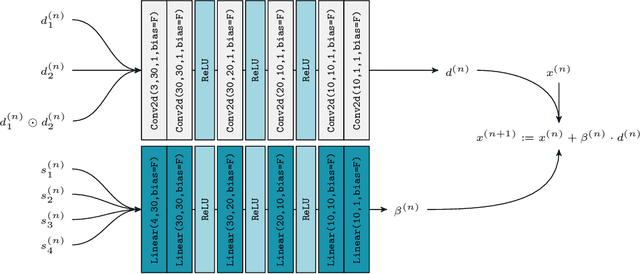
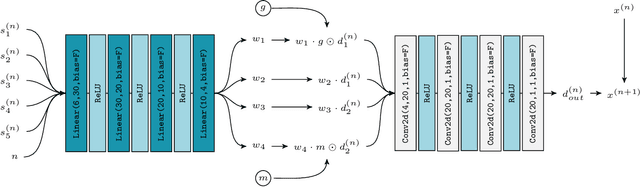
We present a probabilistic model for stochastic iterative algorithms with the use case of optimization algorithms in mind. Based on this model, we present PAC-Bayesian generalization bounds for functions that are defined on the trajectory of the learned algorithm, for example, the expected (non-asymptotic) convergence rate and the expected time to reach the stopping criterion. Thus, not only does this model allow for learning stochastic algorithms based on their empirical performance, it also yields results about their actual convergence rate and their actual convergence time. We stress that, since the model is valid in a more general setting than learning-to-optimize, it is of interest for other fields of application, too. Finally, we conduct five practically relevant experiments, showing the validity of our claims.
Learning-to-Optimize with PAC-Bayesian Guarantees: Theoretical Considerations and Practical Implementation
Apr 04, 2024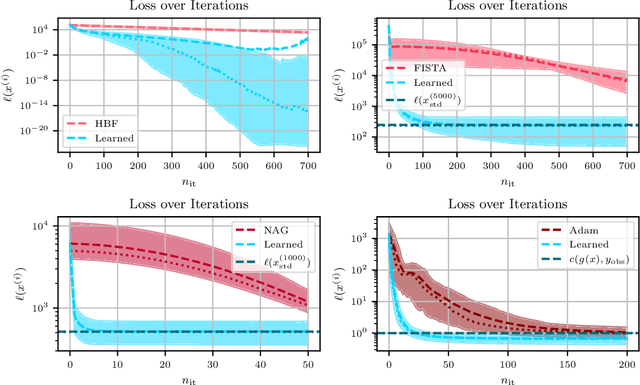
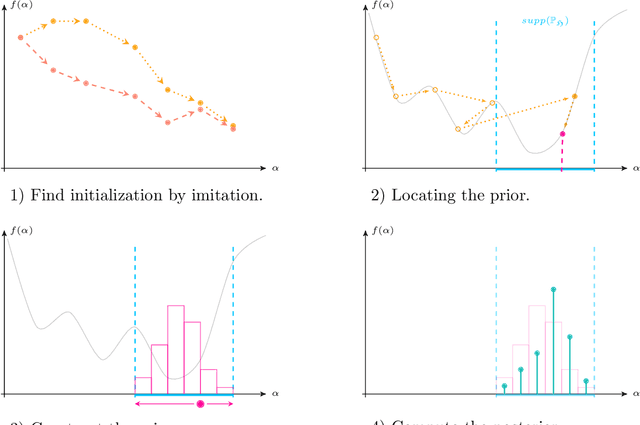
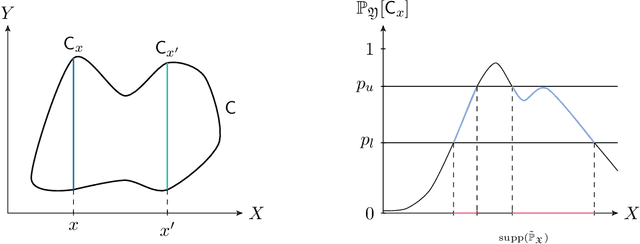

We use the PAC-Bayesian theory for the setting of learning-to-optimize. To the best of our knowledge, we present the first framework to learn optimization algorithms with provable generalization guarantees (PAC-Bayesian bounds) and explicit trade-off between convergence guarantees and convergence speed, which contrasts with the typical worst-case analysis. Our learned optimization algorithms provably outperform related ones derived from a (deterministic) worst-case analysis. The results rely on PAC-Bayesian bounds for general, possibly unbounded loss-functions based on exponential families. Then, we reformulate the learning procedure into a one-dimensional minimization problem and study the possibility to find a global minimum. Furthermore, we provide a concrete algorithmic realization of the framework and new methodologies for learning-to-optimize, and we conduct four practically relevant experiments to support our theory. With this, we showcase that the provided learning framework yields optimization algorithms that provably outperform the state-of-the-art by orders of magnitude.