 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-to-Optimize with PAC-Bayesian Guarantees: Theoretical Considerations and Practical Implementation
Paper and Code
Apr 04, 2024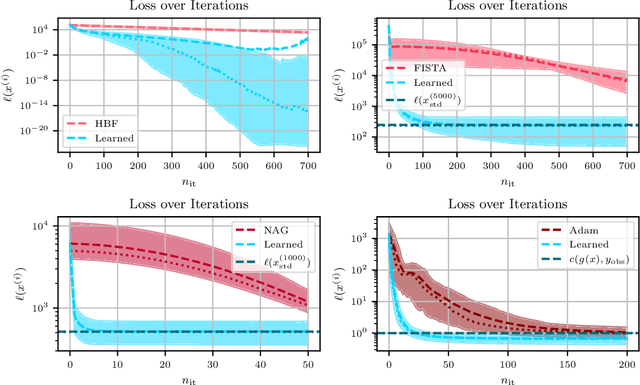

We use the PAC-Bayesian theory for the setting of learning-to-optimize. To the best of our knowledge, we present the first framework to learn optimization algorithms with provable generalization guarantees (PAC-Bayesian bounds) and explicit trade-off between convergence guarantees and convergence speed, which contrasts with the typical worst-case analysis. Our learned optimization algorithms provably outperform related ones derived from a (deterministic) worst-case analysis. The results rely on PAC-Bayesian bounds for general, possibly unbounded loss-functions based on exponential families. Then, we reformulate the learning procedure into a one-dimensional minimization problem and study the possibility to find a global minimum. Furthermore, we provide a concrete algorithmic realization of the framework and new methodologies for learning-to-optimize, and we conduct four practically relevant experiments to support our theory. With this, we showcase that the provided learning framework yields optimization algorithms that provably outperform the state-of-the-art by orders of magnitude.