 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuGen: Adaptable Approach for Generating Labeled Image Datasets using Stable Diffusion Models
Sep 01, 2023Generating high-quality labeled image datasets is crucial for training accurate and robust machine learning models in the field of computer vision. However, the process of manually labeling real images is often time-consuming and costly. To address these challenges associated with dataset generation, we introduce "DiffuGen," a simple and adaptable approach that harnesses the power of stable diffusion models to create labeled image datasets efficiently. By leveraging stable diffusion models, our approach not only ensures the quality of generated datasets but also provides a versatile solution for label generation. In this paper, we present the methodology behind DiffuGen, which combines the capabilities of diffusion models with two distinct labeling techniques: unsupervised and supervised. Distinctively, DiffuGen employs prompt templating for adaptable image generation and textual inversion to enhance diffusion model capabilities.
Lighting and Rotation Invariant Real-time Vehicle Wheel Detector based on YOLOv5
May 28, 2023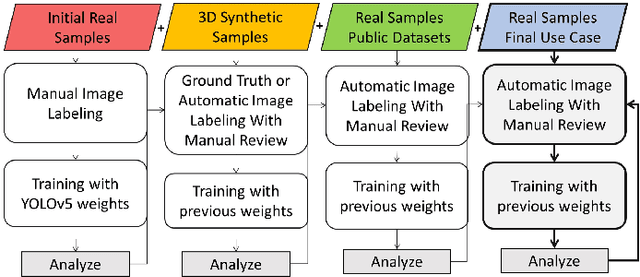
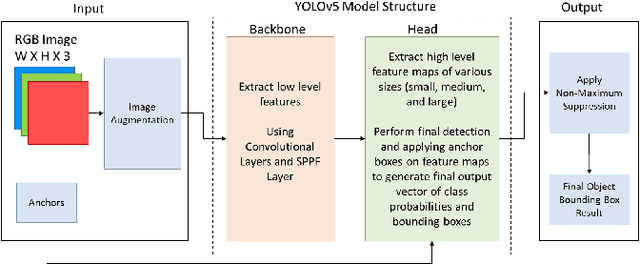
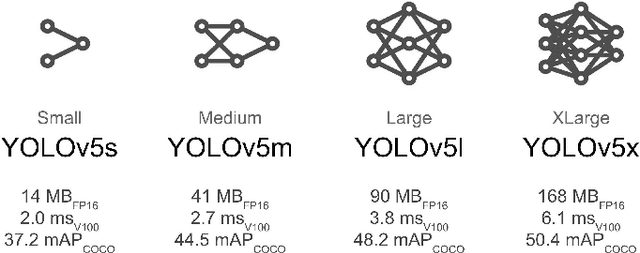

Creating an object detector, in computer vision, has some common challenges when initially developed based on Convolutional Neural Network (CNN) architecture. These challenges are more apparent when creating model that needs to adapt to images captured by various camera orientations, lighting conditions, and environmental changes. The availability of the initial training samples to cover all these conditions can be an enormous challenge with a time and cost burden. While the problem can exist when creating any type of object detection, some types are less common and have no pre-labeled image datasets that exists publicly. Sometime public datasets are not reliable nor comprehensive for a rare object type. Vehicle wheel is one of those example that been chosen to demonstrate the approach of creating a lighting and rotation invariant real-time detector based on YOLOv5 architecture. The objective is to provide a simple approach that could be used as a reference for developing other types of real-time object detectors.
Real-time Object Detection: YOLOv1 Re-Implementation in PyTorch
May 28, 2023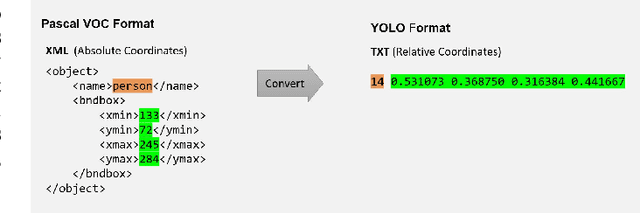

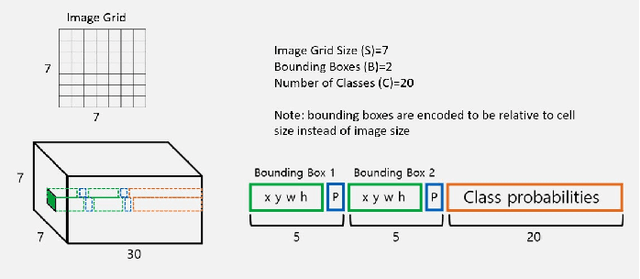
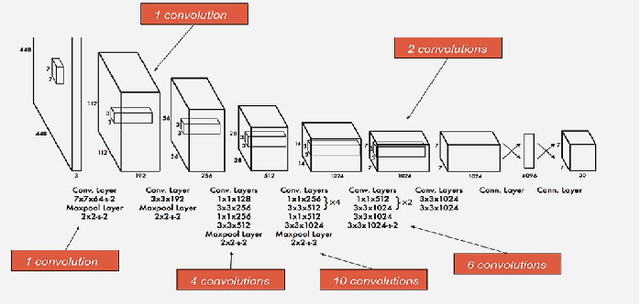
Real-time object detection is a crucial problem to solve when in comes to computer vision systems that needs to make appropriate decision based on detection in a timely manner. I have chosen the YOLO v1 architecture to implement it using PyTorch framework, with goal to familiarize with entire object detection pipeline I attempted different techniques to modify the original architecture to improve the results. Finally, I compare the metrics of my implementation to the original.