 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable transformed ANOVA approximation on the example of the prevention of forest fires
Oct 14, 2021
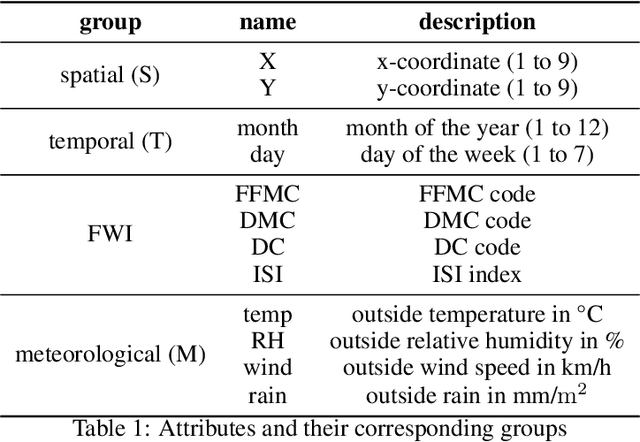
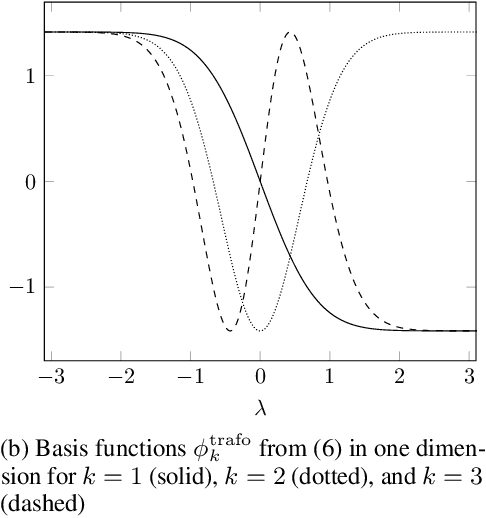
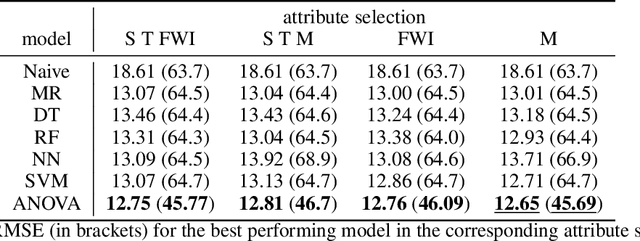
The distribution of data points is a key component in machine learning. In most cases, one uses min-max normalization to obtain nodes in $[0,1]$ or Z-score normalization for standard normal distributed data. In this paper, we apply transformation ideas in order to design a complete orthonormal system in the $\mathrm{L}_2$ space of functions with the standard normal distribution as integration weight. Subsequently, we are able to apply the explainable ANOVA approximation for this basis and use Z-score transformed data in the method. We demonstrate the applicability of this procedure on the well-known forest fires data set from the UCI machine learning repository. The attribute ranking obtained from the ANOVA approximation provides us with crucial information about which variables in the data set are the most important for the detection of fires.
Interpretable Approximation of High-Dimensional Data
Mar 25, 2021
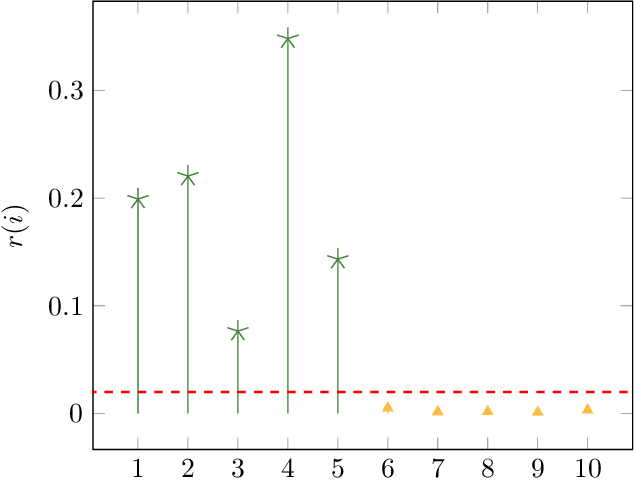
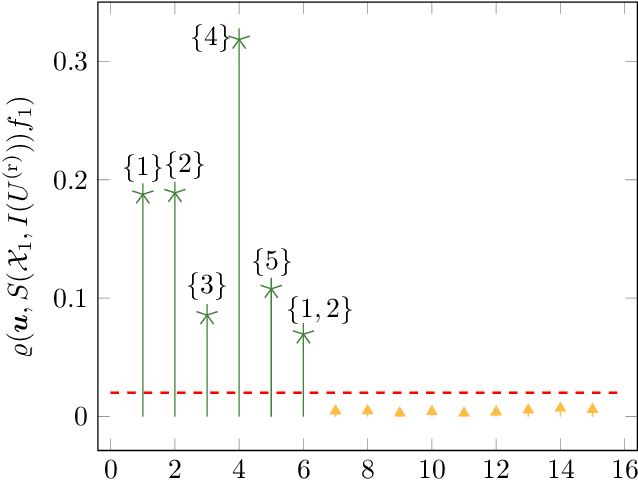

In this paper we apply the previously introduced approximation method based on the ANOVA (analysis of variance) decomposition and Grouped Transformations to synthetic and real data. The advantage of this method is the interpretability of the approximation, i.e., the ability to rank the importance of the attribute interactions or the variable couplings. Moreover, we are able to generate an attribute ranking to identify unimportant variables and reduce the dimensionality of the problem. We compare the method to other approaches on publicly available benchmark datasets.