 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Beyond Intuition: A Testable Criterion for Inherent Explainability
Dec 19, 2025Inherent explainability is the gold standard in Explainable Artificial Intelligence (XAI). However, there is not a consistent definition or test to demonstrate inherent explainability. Work to date either characterises explainability through metrics, or appeals to intuition - "we know it when we see it". We propose a globally applicable criterion for inherent explainability. The criterion uses graph theory for representing and decomposing models for structure-local explanation, and recomposing them into global explanations. We form the structure-local explanations as annotations, a verifiable hypothesis-evidence structure that allows for a range of explanatory methods to be used. This criterion matches existing intuitions on inherent explainability, and provides justifications why a large regression model may not be explainable but a sparse neural network could be. We differentiate explainable -- a model that allows for explanation -- and \textit{explained} -- one that has a verified explanation. Finally, we provide a full explanation of PREDICT -- a Cox proportional hazards model of cardiovascular disease risk, which is in active clinical use in New Zealand. It follows that PREDICT is inherently explainable. This work provides structure to formalise other work on explainability, and allows regulators a flexible but rigorous test that can be used in compliance frameworks.
PropNEAT -- Efficient GPU-Compatible Backpropagation over NeuroEvolutionary Augmenting Topology Networks
Nov 06, 2024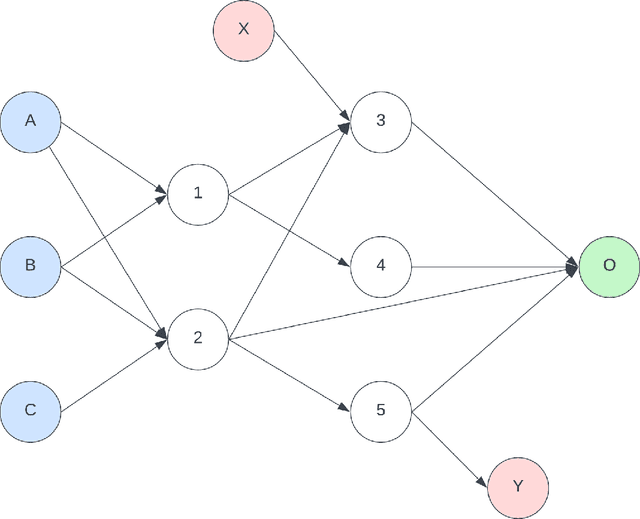



We introduce PropNEAT, a fast backpropagation implementation of NEAT that uses a bidirectional mapping of the genome graph to a layer-based architecture that preserves the NEAT genomes whilst enabling efficient GPU backpropagation. We test PropNEAT on 58 binary classification datasets from the Penn Machine Learning Benchmarks database, comparing the performance against logistic regression, dense neural networks and random forests, as well as a densely retrained variant of the final PropNEAT model. PropNEAT had the second best overall performance, behind Random Forest, though the difference between the models was not statistically significant apart from between Random Forest in comparison with logistic regression and the PropNEAT retrain models. PropNEAT was substantially faster than a naive backpropagation method, and both were substantially faster and had better performance than the original NEAT implementation. We demonstrate that the per-epoch training time for PropNEAT scales linearly with network depth, and is efficient on GPU implementations for backpropagation. This implementation could be extended to support reinforcement learning or convolutional networks, and is able to find sparser and smaller networks with potential for applications in low-power contexts.