 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleaning English Abstracts of Scientific Publications
Dec 30, 2025Scientific abstracts are often used as proxies for the content and thematic focus of research publications. However, a significant share of published abstracts contains extraneous information-such as publisher copyright statements, section headings, author notes, registrations, and bibliometric or bibliographic metadata-that can distort downstream analyses, particularly those involving document similarity or textual embeddings. We introduce an open-source, easy-to-integrate language model designed to clean English-language scientific abstracts by automatically identifying and removing such clutter. We demonstrate that our model is both conservative and precise, alters similarity rankings of cleaned abstracts and improves information content of standard-length embeddings.
Tracing the Flow of Knowledge From Science to Technology Using Deep Learning
Dec 30, 2025We develop a language similarity model suitable for working with patents and scientific publications at the same time. In a horse race-style evaluation, we subject eight language (similarity) models to predict credible Patent-Paper Citations. We find that our Pat-SPECTER model performs best, which is the SPECTER2 model fine-tuned on patents. In two real-world scenarios (separating patent-paper-pairs and predicting patent-paper-pairs) we demonstrate the capabilities of the Pat-SPECTER. We finally test the hypothesis that US patents cite papers that are semantically less similar than in other large jurisdictions, which we posit is because of the duty of candor. The model is open for the academic community and practitioners alike.
PaECTER: Patent-level Representation Learning using Citation-informed Transformers
Feb 29, 2024PaECTER is a publicly available, open-source document-level encoder specific for patents. We fine-tune BERT for Patents with examiner-added citation information to generate numerical representations for patent documents. PaECTER performs better in similarity tasks than current state-of-the-art models used in the patent domain. More specifically, our model outperforms the next-best patent specific pre-trained language model (BERT for Patents) on our patent citation prediction test dataset on two different rank evaluation metrics. PaECTER predicts at least one most similar patent at a rank of 1.32 on average when compared against 25 irrelevant patents. Numerical representations generated by PaECTER from patent text can be used for downstream tasks such as classification, tracing knowledge flows, or semantic similarity search. Semantic similarity search is especially relevant in the context of prior art search for both inventors and patent examiners. PaECTER is available on Hugging Face.
Logic Mill -- A Knowledge Navigation System
Dec 31, 2022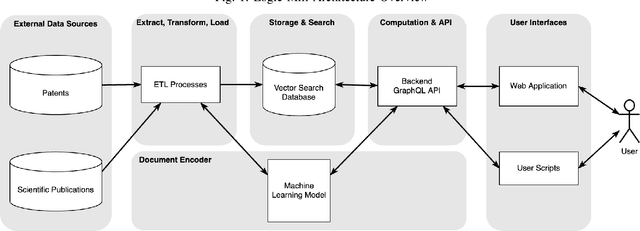
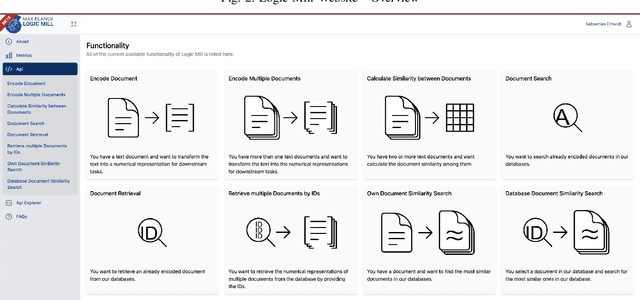
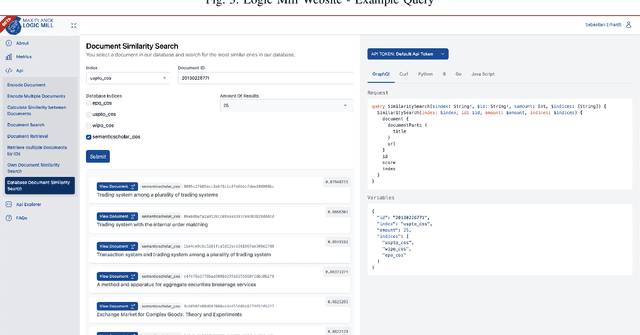

Logic Mill is a scalable and openly accessible software system that identifies semantically similar documents within either one domain-specific corpus or multi-domain corpora. It uses advanced Natural Language Processing (NLP) techniques to generate numerical representations of documents. Currently it leverages a large pre-trained language model to generate these document representations. The system focuses on scientific publications and patent documents and contains more than 200 million documents. It is easily accessible via a simple Application Programming Interface (API) or via a web interface. Moreover, it is continuously being updated and can be extended to text corpora from other domains. We see this system as a general-purpose tool for future research applications in the social sciences and other domains.