 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum Correction: Acoustic Scene Classification with Mismatched Recording Devices
May 25, 2021
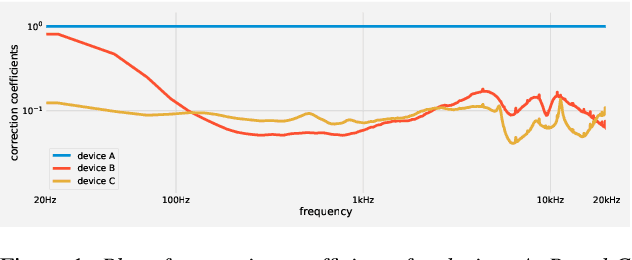

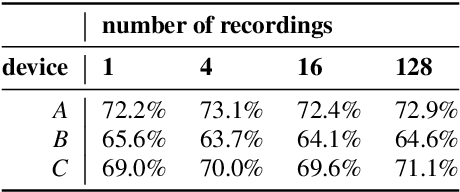
Machine learning algorithms, when trained on audio recordings from a limited set of devices, may not generalize well to samples recorded using other devices with different frequency responses. In this work, a relatively straightforward method is introduced to address this problem. Two variants of the approach are presented. First requires aligned examples from multiple devices, the second approach alleviates this requirement. This method works for both time and frequency domain representations of audio recordings. Further, a relation to standardization and Cepstral Mean Subtraction is analysed. The proposed approach becomes effective even when very few examples are provided. This method was developed during the Detection and Classification of Acoustic Scenes and Events (DCASE) 2019 challenge and won the 1st place in the scenario with mis-matched recording devices with the accuracy of 75%. Source code for the experiments can be found online.
* 5 pages, 1 figure, published at Interspeech 2020, see https://isca-speech.org/archive/Interspeech_2020/abstracts/3088.html
Deep Learning Based Open Set Acoustic Scene Classification
Aug 17, 2020
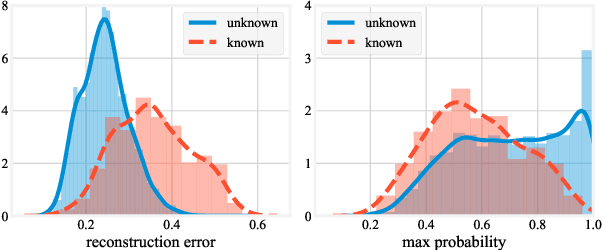
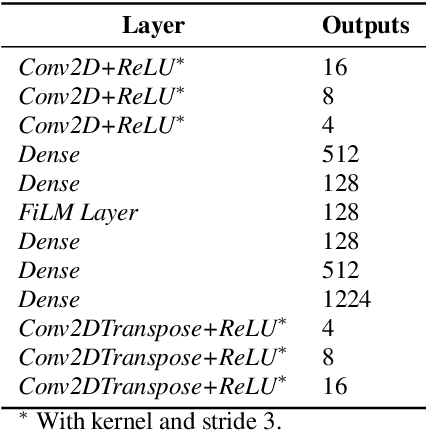
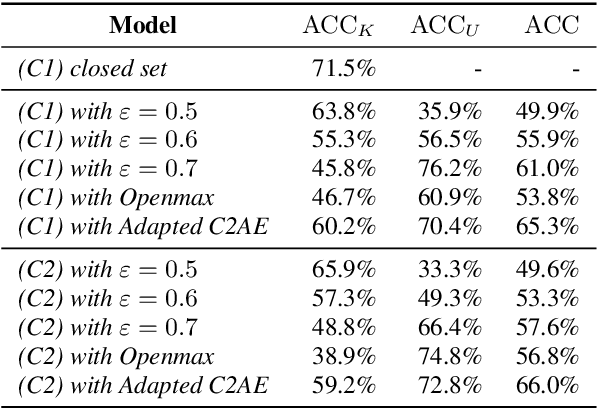
In this work, we compare the performance of three selected techniques in open set acoustic scenes classification (ASC). We test thresholding of the softmax output of a deep network classifier, which is the most popular technique nowadays employed in ASC. Further we compare the results with the Openmax classifier which is derived from the computer vision field. As the third model, we use the Adapted Class-Conditioned Autoencoder (Adapted C2AE) which is our variation of another computer vision related technique called C2AE. Adapted C2AE encompasses a more fair comparison of the given experiments and simplifies the original inference procedure, making it more applicable in the real-life scenarios. We also analyse two training scenarios: without additional knowledge of unknown classes and another where a limited subset of examples from the unknown classes is available. We find that the C2AE based method outperforms the thresholding and Openmax, obtaining $85.5\%$ Area Under the Receiver Operating Characteristic curve (AUROC) and $66\%$ of open set accuracy on data used in Detection and Classification of Acoustic Scenes and Events Challenge 2019 Task 1C.