 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Semantic Decoupled Modulation of Global Geospatial Embeddings for High-Resolution Remote Sensing Mapping
Apr 22, 2026Fine-grained high-resolution remote sensing mapping typically relies on localized visual features, which restricts cross-domain generalizability and often leads to fragmented predictions of large-scale land covers. While global geospatial foundation models offer powerful, generalizable representations, directly fusing their high-dimensional implicit embeddings with high-resolution visual features frequently triggers feature interference and spatial structure degradation due to a severe semantic-spatial gap. To overcome these limitations, we propose a Structure-Semantic Decoupled Modulation (SSDM) framework, which decouples global geospatial representations into two complementary cross-modal injection pathways. First, the structural prior modulation branch introduces the macroscopic receptive field priors from global representations into the self-attention modules of the high-resolution encoder. By guiding local feature extraction with holistic structural constraints, it effectively suppresses prediction fragmentation caused by high-frequency detail noise and excessive intra-class variance. Second, the global semantic injection branch explicitly aligns holistic context with the deep high-resolution feature space and directly supplements global semantics via cross-modal integration, thereby significantly enhancing the semantic consistency and category-level discrimination of complex land covers. Extensive experiments demonstrate that our method achieves state-of-the-art performance compared to existing cross-modal fusion approaches. By unleashing the potential of global embeddings, SSDM consistently improves high-resolution mapping accuracy across diverse scenarios, providing a universal and effective paradigm for integrating geospatial foundation models into high-resolution vision tasks.
SL-FAC: A Communication-Efficient Split Learning Framework with Frequency-Aware Compression
Apr 08, 2026The growing complexity of neural networks hinders the deployment of distributed machine learning on resource-constrained devices. Split learning (SL) offers a promising solution by partitioning the large model and offloading the primary training workload from edge devices to an edge server. However, the increasing number of participating devices and model complexity leads to significant communication overhead from the transmission of smashed data (e.g., activations and gradients), which constitutes a critical bottleneck for SL. To tackle this challenge, we propose SL-FAC, a communication-efficient SL framework comprising two key components: adaptive frequency decomposition (AFD) and frequency-based quantization compression (FQC). AFD first transforms the smashed data into the frequency domain and decomposes it into spectral components with distinct information. FQC then applies customized quantization bit widths to each component based on its spectral energy distribution. This collaborative approach enables SL-FAC to achieve significant communication reduction while strategically preserving the information most crucial for model convergence. Extensive experiments confirm the superior performance of SL-FAC for improving the training efficiency.
Conflict-Aware Client Selection for Multi-Server Federated Learning
Feb 02, 2026Federated learning (FL) has emerged as a promising distributed machine learning (ML) that enables collaborative model training across clients without exposing raw data, thereby preserving user privacy and reducing communication costs. Despite these benefits, traditional single-server FL suffers from high communication latency due to the aggregation of models from a large number of clients. While multi-server FL distributes workloads across edge servers, overlapping client coverage and uncoordinated selection often lead to resource contention, causing bandwidth conflicts and training failures. To address these limitations, we propose a decentralized reinforcement learning with conflict risk prediction, named RL CRP, to optimize client selection in multi-server FL systems. Specifically, each server estimates the likelihood of client selection conflicts using a categorical hidden Markov model based on its sparse historical client selection sequence. Then, a fairness-aware reward mechanism is incorporated to promote long-term client participation for minimizing training latency and resource contention. Extensive experiments demonstrate that the proposed RL-CRP framework effectively reduces inter-server conflicts and significantly improves training efficiency in terms of convergence speed and communication cost.
NSC-SL: A Bandwidth-Aware Neural Subspace Compression for Communication-Efficient Split Learning
Feb 02, 2026The expanding scale of neural networks poses a major challenge for distributed machine learning, particularly under limited communication resources. While split learning (SL) alleviates client computational burden by distributing model layers between clients and server, it incurs substantial communication overhead from frequent transmission of intermediate activations and gradients. To tackle this issue, we propose NSC-SL, a bandwidth-aware adaptive compression algorithm for communication-efficient SL. NSC-SL first dynamically determines the optimal rank of low-rank approximation based on the singular value distribution for adapting real-time bandwidth constraints. Then, NSC-SL performs error-compensated tensor factorization using alternating orthogonal iteration with residual feedback, effectively minimizing truncation loss. The collaborative mechanisms enable NSC-SL to achieve high compression ratios while preserving semantic-rich information essential for convergence. Extensive experiments demonstrate the superb performance of NSC-SL.
RS-Prune: Training-Free Data Pruning at High Ratios for Efficient Remote Sensing Diffusion Foundation Models
Dec 29, 2025Diffusion-based remote sensing (RS) generative foundation models are cruial for downstream tasks. However, these models rely on large amounts of globally representative data, which often contain redundancy, noise, and class imbalance, reducing training efficiency and preventing convergence. Existing RS diffusion foundation models typically aggregate multiple classification datasets or apply simplistic deduplication, overlooking the distributional requirements of generation modeling and the heterogeneity of RS imagery. To address these limitations, we propose a training-free, two-stage data pruning approach that quickly select a high-quality subset under high pruning ratios, enabling a preliminary foundation model to converge rapidly and serve as a versatile backbone for generation, downstream fine-tuning, and other applications. Our method jointly considers local information content with global scene-level diversity and representativeness. First, an entropy-based criterion efficiently removes low-information samples. Next, leveraging RS scene classification datasets as reference benchmarks, we perform scene-aware clustering with stratified sampling to improve clustering effectiveness while reducing computational costs on large-scale unlabeled data. Finally, by balancing cluster-level uniformity and sample representativeness, the method enables fine-grained selection under high pruning ratios while preserving overall diversity and representativeness. Experiments show that, even after pruning 85\% of the training data, our method significantly improves convergence and generation quality. Furthermore, diffusion foundation models trained with our method consistently achieve state-of-the-art performance across downstream tasks, including super-resolution and semantic image synthesis. This data pruning paradigm offers practical guidance for developing RS generative foundation models.
Alchemist: Unlocking Efficiency in Text-to-Image Model Training via Meta-Gradient Data Selection
Dec 18, 2025Recent advances in Text-to-Image (T2I) generative models, such as Imagen, Stable Diffusion, and FLUX, have led to remarkable improvements in visual quality. However, their performance is fundamentally limited by the quality of training data. Web-crawled and synthetic image datasets often contain low-quality or redundant samples, which lead to degraded visual fidelity, unstable training, and inefficient computation. Hence, effective data selection is crucial for improving data efficiency. Existing approaches rely on costly manual curation or heuristic scoring based on single-dimensional features in Text-to-Image data filtering. Although meta-learning based method has been explored in LLM, there is no adaptation for image modalities. To this end, we propose **Alchemist**, a meta-gradient-based framework to select a suitable subset from large-scale text-image data pairs. Our approach automatically learns to assess the influence of each sample by iteratively optimizing the model from a data-centric perspective. Alchemist consists of two key stages: data rating and data pruning. We train a lightweight rater to estimate each sample's influence based on gradient information, enhanced with multi-granularity perception. We then use the Shift-Gsampling strategy to select informative subsets for efficient model training. Alchemist is the first automatic, scalable, meta-gradient-based data selection framework for Text-to-Image model training. Experiments on both synthetic and web-crawled datasets demonstrate that Alchemist consistently improves visual quality and downstream performance. Training on an Alchemist-selected 50% of the data can outperform training on the full dataset.
FilmWeaver: Weaving Consistent Multi-Shot Videos with Cache-Guided Autoregressive Diffusion
Dec 12, 2025Current video generation models perform well at single-shot synthesis but struggle with multi-shot videos, facing critical challenges in maintaining character and background consistency across shots and flexibly generating videos of arbitrary length and shot count. To address these limitations, we introduce \textbf{FilmWeaver}, a novel framework designed to generate consistent, multi-shot videos of arbitrary length. First, it employs an autoregressive diffusion paradigm to achieve arbitrary-length video generation. To address the challenge of consistency, our key insight is to decouple the problem into inter-shot consistency and intra-shot coherence. We achieve this through a dual-level cache mechanism: a shot memory caches keyframes from preceding shots to maintain character and scene identity, while a temporal memory retains a history of frames from the current shot to ensure smooth, continuous motion. The proposed framework allows for flexible, multi-round user interaction to create multi-shot videos. Furthermore, due to this decoupled design, our method demonstrates high versatility by supporting downstream tasks such as multi-concept injection and video extension. To facilitate the training of our consistency-aware method, we also developed a comprehensive pipeline to construct a high-quality multi-shot video dataset. Extensive experimental results demonstrate that our method surpasses existing approaches on metrics for both consistency and aesthetic quality, opening up new possibilities for creating more consistent, controllable, and narrative-driven video content. Project Page: https://filmweaver.github.io
Peer Offloading with Delayed Feedback in Fog Networks
Nov 24, 2020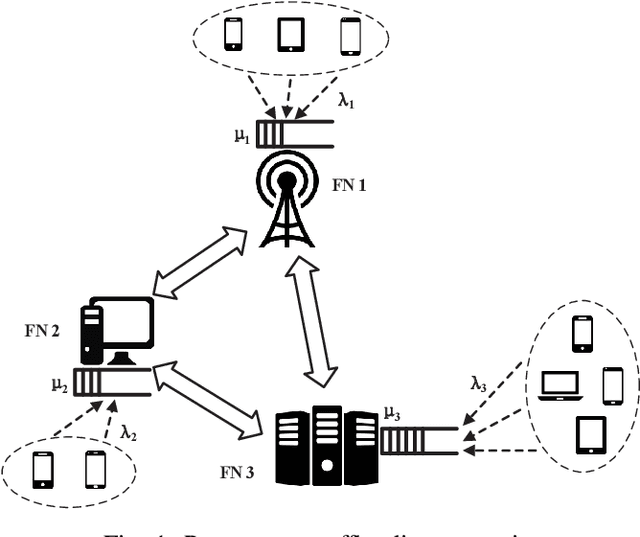
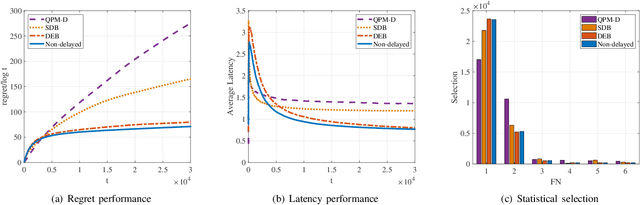

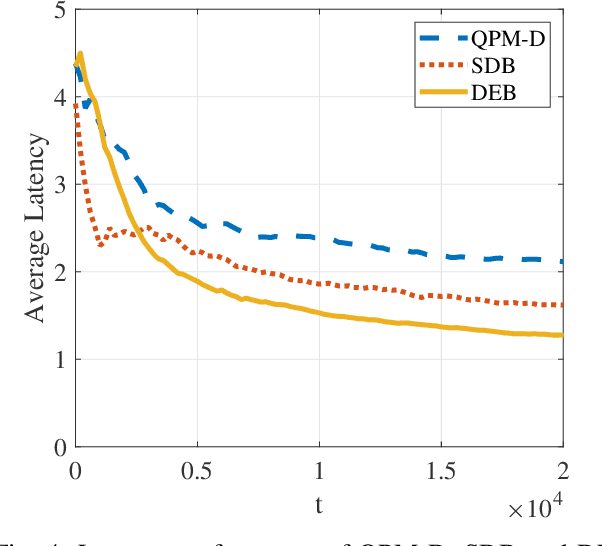
Comparing to cloud computing, fog computing performs computation and services at the edge of networks, thus relieving the computation burden of the data center and reducing the task latency of end devices. Computation latency is a crucial performance metric in fog computing, especially for real-time applications. In this paper, we study a peer computation offloading problem for a fog network with unknown dynamics. In this scenario, each fog node (FN) can offload their computation tasks to neighboring FNs in a time slot manner. The offloading latency, however, could not be fed back to the task dispatcher instantaneously due to the uncertainty of the processing time in peer FNs. Besides, peer competition occurs when different FNs offload tasks to one FN at the same time. To tackle the above difficulties, we model the computation offloading problem as a sequential FN selection problem with delayed information feedback. Using adversarial multi-arm bandit framework, we construct an online learning policy to deal with delayed information feedback. Different contention resolution approaches are considered to resolve peer competition. Performance analysis shows that the regret of the proposed algorithm, or the performance loss with suboptimal FN selections, achieves a sub-linear order, suggesting an optimal FN selection policy. In addition, we prove that the proposed strategy can result in a Nash equilibrium (NE) with all FNs playing the same policy. Simulation results validate the effectiveness of the proposed policy.
Federated learning with class imbalance reduction
Nov 23, 2020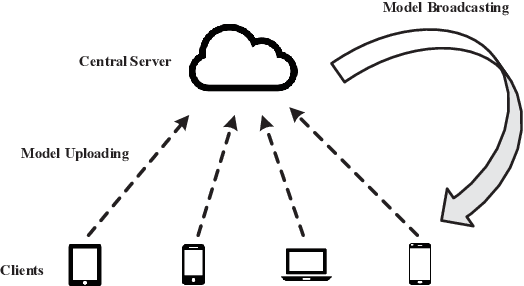
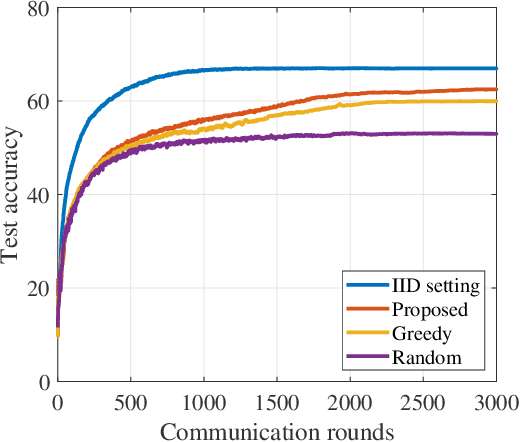
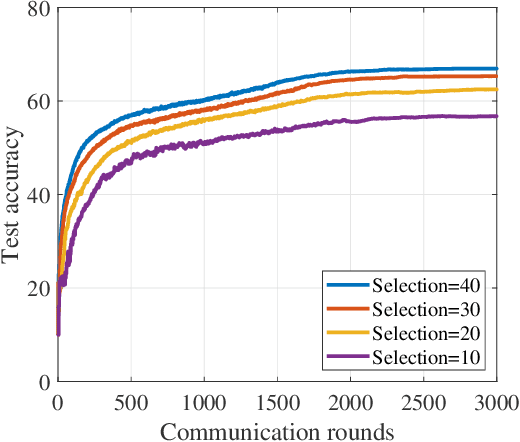
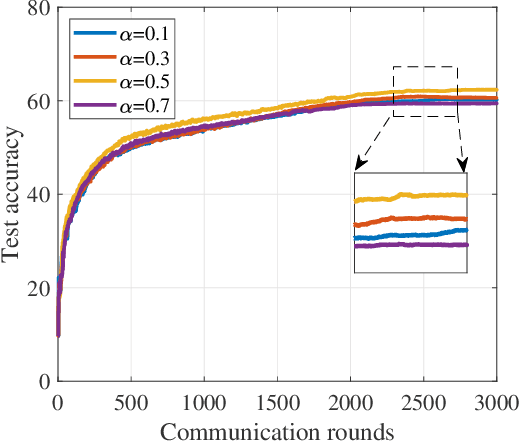
Federated learning (FL) is a promising technique that enables a large amount of edge computing devices to collaboratively train a global learning model. Due to privacy concerns, the raw data on devices could not be available for centralized server. Constrained by the spectrum limitation and computation capacity, only a subset of devices can be engaged to train and transmit the trained model to centralized server for aggregation. Since the local data distribution varies among all devices, class imbalance problem arises along with the unfavorable client selection, resulting in a slow converge rate of the global model. In this paper, an estimation scheme is designed to reveal the class distribution without the awareness of raw data. Based on the scheme, a device selection algorithm towards minimal class imbalance is proposed, thus can improve the convergence performance of the global model. Simulation results demonstrate the effectiveness of the proposed algorithm.