 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring feature importance with uncertainties in high-dimensional data
Sep 20, 2021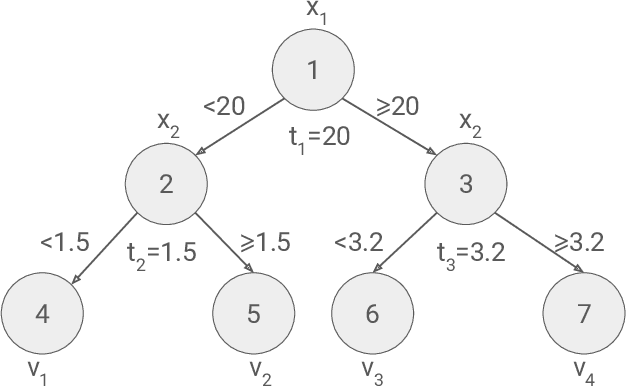


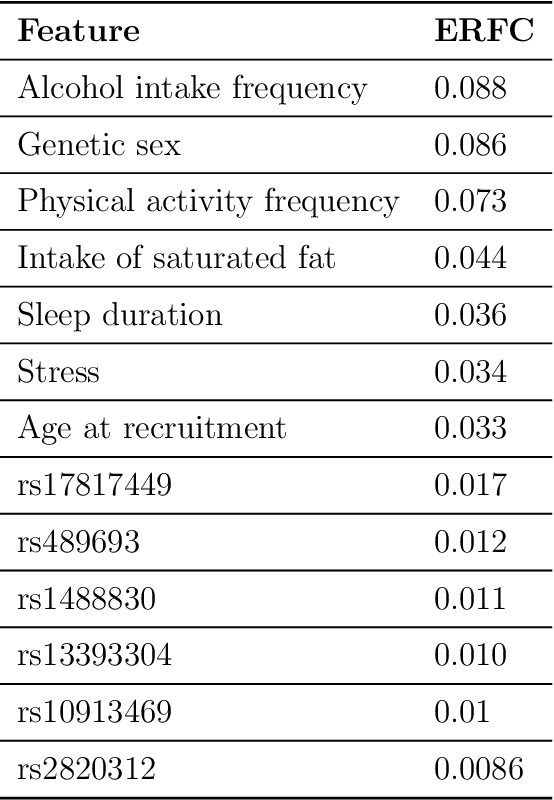
Estimating feature importance is a significant aspect of explaining data-based models. Besides explaining the model itself, an equally relevant question is which features are important in the underlying data generating process. We present a Shapley value based framework for inferring the importance of individual features, including uncertainty in the estimator. We build upon the recently published feature importance measure of SAGE (Shapley additive global importance) and introduce sub-SAGE which can be estimated without resampling for tree-based models. We argue that the uncertainties can be estimated from bootstrapping and demonstrate the approach for tree ensemble methods. The framework is exemplified on synthetic data as well as high-dimensional genomics data.