 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Open-Source Language Models for Efficient Question Answering in Industrial Applications
Jun 19, 2024

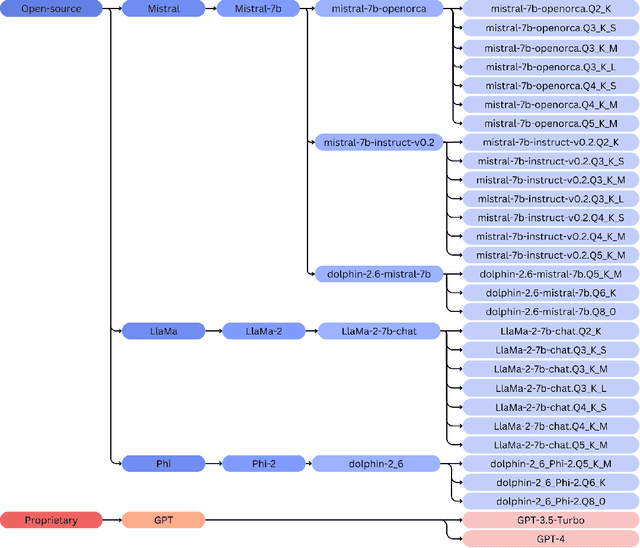

In the rapidly evolving landscape of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated remarkable capabilities in tasks such as question answering (QA). However, the accessibility and practicality of utilizing these models for industrial applications pose significant challenges, particularly concerning cost-effectiveness, inference speed, and resource efficiency. This paper presents a comprehensive benchmarking study comparing open-source LLMs with their non-open-source counterparts on the task of question answering. Our objective is to identify open-source alternatives capable of delivering comparable performance to proprietary models while being lightweight in terms of resource requirements and suitable for Central Processing Unit (CPU)-based inference. Through rigorous evaluation across various metrics including accuracy, inference speed, and resource consumption, we aim to provide insights into selecting efficient LLMs for real-world applications. Our findings shed light on viable open-source alternatives that offer acceptable performance and efficiency, addressing the pressing need for accessible and efficient NLP solutions in industry settings.
Low-Cost Language Models: Survey and Performance Evaluation on Python Code Generation
Apr 17, 2024



Large Language Models (LLMs) have become the go-to solution for many Natural Language Processing (NLP) tasks due to their ability to tackle various problems and produce high-quality results. Specifically, they are increasingly used to automatically generate code, easing the burden on developers by handling repetitive tasks. However, this improvement in quality has led to high computational and memory demands, making LLMs inaccessible to users with limited resources. In this paper, we focus on Central Processing Unit (CPU)-compatible models and conduct a thorough semi-manual evaluation of their strengths and weaknesses in generating Python code. We enhance their performance by introducing a Chain-of-Thought prompt that guides the model in problem-solving. Additionally, we propose a dataset of 60 programming problems with varying difficulty levels for evaluation purposes. Our assessment also includes testing these models on two state-of-the-art datasets: HumanEval and EvalPlus. We commit to sharing our dataset and experimental results publicly to ensure transparency.