 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Workflows: Automating Business Processes
Dec 04, 2024As businesses increasingly rely on automation to streamline operations, the limitations of Robotic Process Automation (RPA) have become apparent, particularly its dependence on expert knowledge and inability to handle complex decision-making tasks. Recent advancements in Artificial Intelligence (AI), particularly Generative AI (GenAI) and Large Language Models (LLMs), have paved the way for Intelligent Automation (IA), which integrates cognitive capabilities to overcome the shortcomings of RPA. This paper introduces Text2Workflow, a novel method that automatically generates workflows from natural language user requests. Unlike traditional automation approaches, Text2Workflow offers a generalized solution for automating any business process, translating user inputs into a sequence of executable steps represented in JavaScript Object Notation (JSON) format. Leveraging the decision-making and instruction-following capabilities of LLMs, this method provides a scalable, adaptable framework that enables users to visualize and execute workflows with minimal manual intervention. This research outlines the Text2Workflow methodology and its broader implications for automating complex business processes.
Benchmarking Open-Source Language Models for Efficient Question Answering in Industrial Applications
Jun 19, 2024

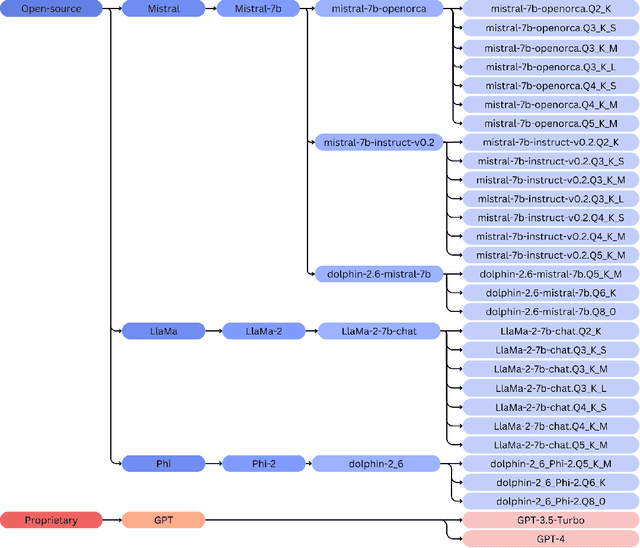

In the rapidly evolving landscape of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated remarkable capabilities in tasks such as question answering (QA). However, the accessibility and practicality of utilizing these models for industrial applications pose significant challenges, particularly concerning cost-effectiveness, inference speed, and resource efficiency. This paper presents a comprehensive benchmarking study comparing open-source LLMs with their non-open-source counterparts on the task of question answering. Our objective is to identify open-source alternatives capable of delivering comparable performance to proprietary models while being lightweight in terms of resource requirements and suitable for Central Processing Unit (CPU)-based inference. Through rigorous evaluation across various metrics including accuracy, inference speed, and resource consumption, we aim to provide insights into selecting efficient LLMs for real-world applications. Our findings shed light on viable open-source alternatives that offer acceptable performance and efficiency, addressing the pressing need for accessible and efficient NLP solutions in industry settings.
Low-Cost Language Models: Survey and Performance Evaluation on Python Code Generation
Apr 17, 2024



Large Language Models (LLMs) have become the go-to solution for many Natural Language Processing (NLP) tasks due to their ability to tackle various problems and produce high-quality results. Specifically, they are increasingly used to automatically generate code, easing the burden on developers by handling repetitive tasks. However, this improvement in quality has led to high computational and memory demands, making LLMs inaccessible to users with limited resources. In this paper, we focus on Central Processing Unit (CPU)-compatible models and conduct a thorough semi-manual evaluation of their strengths and weaknesses in generating Python code. We enhance their performance by introducing a Chain-of-Thought prompt that guides the model in problem-solving. Additionally, we propose a dataset of 60 programming problems with varying difficulty levels for evaluation purposes. Our assessment also includes testing these models on two state-of-the-art datasets: HumanEval and EvalPlus. We commit to sharing our dataset and experimental results publicly to ensure transparency.
Entity Identifier: A Natural Text Parsing-based Framework For Entity Relation Extraction
Jul 10, 2023The field of programming has a diversity of paradigms that are used according to the working framework. While current neural code generation methods are able to learn and generate code directly from text, we believe that this approach is not optimal for certain code tasks, particularly the generation of classes in an object-oriented project. Specifically, we use natural language processing techniques to extract structured information from requirements descriptions, in order to automate the generation of CRUD (Create, Read, Update, Delete) class code. To facilitate this process, we introduce a pipeline for extracting entity and relation information, as well as a representation called an "Entity Tree" to model this information. We also create a dataset to evaluate the effectiveness of our approach.
A Comprehensive Review of State-of-The-Art Methods for Java Code Generation from Natural Language Text
Jun 10, 2023Java Code Generation consists in generating automatically Java code from a Natural Language Text. This NLP task helps in increasing programmers' productivity by providing them with immediate solutions to the simplest and most repetitive tasks. Code generation is a challenging task because of the hard syntactic rules and the necessity of a deep understanding of the semantic aspect of the programming language. Many works tried to tackle this task using either RNN-based, or Transformer-based models. The latter achieved remarkable advancement in the domain and they can be divided into three groups: (1) encoder-only models, (2) decoder-only models, and (3) encoder-decoder models. In this paper, we provide a comprehensive review of the evolution and progress of deep learning models in Java code generation task. We focus on the most important methods and present their merits and limitations, as well as the objective functions used by the community. In addition, we provide a detailed description of datasets and evaluation metrics used in the literature. Finally, we discuss results of different models on CONCODE dataset, then propose some future directions.
* Published at Elsevier's Natural Language Processing Journal
GPT-3.5 vs GPT-4: Evaluating ChatGPT's Reasoning Performance in Zero-shot Learning
May 21, 2023Large Language Models (LLMs) have exhibited remarkable performance on various Natural Language Processing (NLP) tasks. However, there is a current hot debate regarding their reasoning capacity. In this paper, we examine the performance of GPT-3.5 and GPT-4 models, by performing a thorough technical evaluation on different reasoning tasks across eleven distinct datasets. Our findings show that GPT-4 outperforms GPT-3.5 in zero-shot learning throughout almost all evaluated tasks. In addition, we note that both models exhibit limited performance in Inductive, Mathematical, and Multi-hop Reasoning Tasks. While it may seem intuitive that the GPT-4 model would outperform GPT-3.5 given its size and efficiency in various NLP tasks, our paper offers empirical evidence to support this claim. We provide a detailed and comprehensive analysis of the results from both models to further support our findings. In addition, we propose a set of engineered prompts that improves performance of both models on zero-shot learning.
JaCoText: A Pretrained Model for Java Code-Text Generation
Mar 22, 2023Pretrained transformer-based models have shown high performance in natural language generation task. However, a new wave of interest has surged: automatic programming language generation. This task consists of translating natural language instructions to a programming code. Despite the fact that well-known pretrained models on language generation have achieved good performance in learning programming languages, effort is still needed in automatic code generation. In this paper, we introduce JaCoText, a model based on Transformers neural network. It aims to generate java source code from natural language text. JaCoText leverages advantages of both natural language and code generation models. More specifically, we study some findings from the state of the art and use them to (1) initialize our model from powerful pretrained models, (2) explore additional pretraining on our java dataset, (3) carry out experiments combining the unimodal and bimodal data in the training, and (4) scale the input and output length during the fine-tuning of the model. Conducted experiments on CONCODE dataset show that JaCoText achieves new state-of-the-art results.
* International Conference on Code Generation and Implementation Volume: 17