 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Freezing: A Regularization Approach for Fully Connected Layers with an Application in EEG Classification
Jun 12, 2023In the realm of EEG decoding, enhancing the performance of artificial neural networks (ANNs) carries significant potential. This study introduces a novel approach, termed "weight freezing", that is anchored on the principles of ANN regularization and neuroscience prior knowledge. The concept of weight freezing revolves around the idea of reducing certain neurons' influence on the decision-making process for a specific EEG task by freezing specific weights in the fully connected layer during the backpropagation process. This is actualized through the use of a mask matrix and a threshold to determine the proportion of weights to be frozen during backpropagation. Moreover, by setting the masked weights to zero, weight freezing can not only realize sparse connections in networks with a fully connected layer as the classifier but also function as an efficacious regularization method for fully connected layers. Through experiments involving three distinct ANN architectures and three widely recognized EEG datasets, we validate the potency of weight freezing. Our method significantly surpasses previous peak performances in classification accuracy across all examined datasets. Supplementary control experiments offer insights into performance differences pre and post weight freezing implementation and scrutinize the influence of the threshold in the weight freezing process. Our study underscores the superior efficacy of weight freezing compared to traditional fully connected networks for EEG feature classification tasks. With its proven effectiveness, this innovative approach holds substantial promise for contributing to future strides in EEG decoding research.
Time-space-frequency feature Fusion for 3-channel motor imagery classification
Apr 04, 2023Low-channel EEG devices are crucial for portable and entertainment applications. However, the low spatial resolution of EEG presents challenges in decoding low-channel motor imagery. This study introduces TSFF-Net, a novel network architecture that integrates time-space-frequency features, effectively compensating for the limitations of single-mode feature extraction networks based on time-series or time-frequency modalities. TSFF-Net comprises four main components: time-frequency representation, time-frequency feature extraction, time-space feature extraction, and feature fusion and classification. Time-frequency representation and feature extraction transform raw EEG signals into time-frequency spectrograms and extract relevant features. The time-space network processes time-series EEG trials as input and extracts temporal-spatial features. Feature fusion employs MMD loss to constrain the distribution of time-frequency and time-space features in the Reproducing Kernel Hilbert Space, subsequently combining these features using a weighted fusion approach to obtain effective time-space-frequency features. Moreover, few studies have explored the decoding of three-channel motor imagery based on time-frequency spectrograms. This study proposes a shallow, lightweight decoding architecture (TSFF-img) based on time-frequency spectrograms and compares its classification performance in low-channel motor imagery with other methods using two publicly available datasets. Experimental results demonstrate that TSFF-Net not only compensates for the shortcomings of single-mode feature extraction networks in EEG decoding, but also outperforms other state-of-the-art methods. Overall, TSFF-Net offers considerable advantages in decoding low-channel motor imagery and provides valuable insights for algorithmically enhancing low-channel EEG decoding.
LMDA-Net:A lightweight multi-dimensional attention network for general EEG-based brain-computer interface paradigms and interpretability
Mar 29, 2023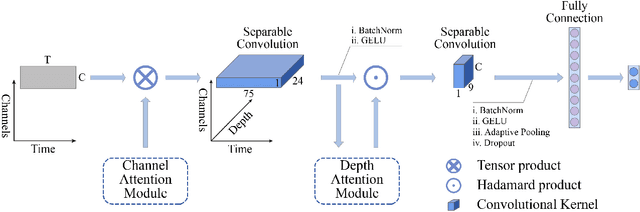
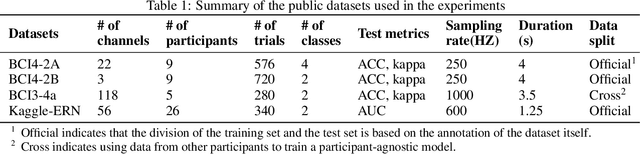
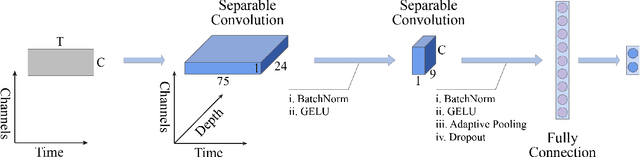
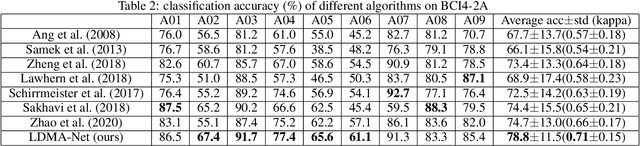
EEG-based recognition of activities and states involves the use of prior neuroscience knowledge to generate quantitative EEG features, which may limit BCI performance. Although neural network-based methods can effectively extract features, they often encounter issues such as poor generalization across datasets, high predicting volatility, and low model interpretability. Hence, we propose a novel lightweight multi-dimensional attention network, called LMDA-Net. By incorporating two novel attention modules designed specifically for EEG signals, the channel attention module and the depth attention module, LMDA-Net can effectively integrate features from multiple dimensions, resulting in improved classification performance across various BCI tasks. LMDA-Net was evaluated on four high-impact public datasets, including motor imagery (MI) and P300-Speller paradigms, and was compared with other representative models. The experimental results demonstrate that LMDA-Net outperforms other representative methods in terms of classification accuracy and predicting volatility, achieving the highest accuracy in all datasets within 300 training epochs. Ablation experiments further confirm the effectiveness of the channel attention module and the depth attention module. To facilitate an in-depth understanding of the features extracted by LMDA-Net, we propose class-specific neural network feature interpretability algorithms that are suitable for event-related potentials (ERPs) and event-related desynchronization/synchronization (ERD/ERS). By mapping the output of the specific layer of LMDA-Net to the time or spatial domain through class activation maps, the resulting feature visualizations can provide interpretable analysis and establish connections with EEG time-spatial analysis in neuroscience. In summary, LMDA-Net shows great potential as a general online decoding model for various EEG tasks.
Priming Cross-Session Motor Imagery Classification with A Universal Deep Domain Adaptation Framework
Feb 19, 2022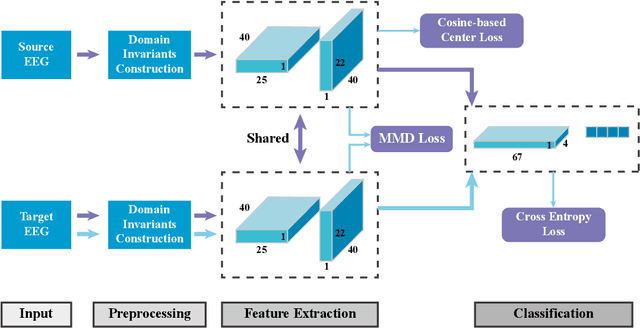
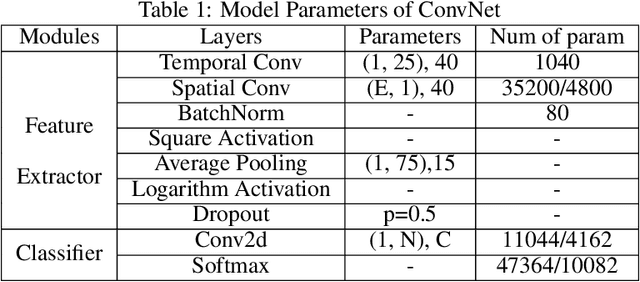
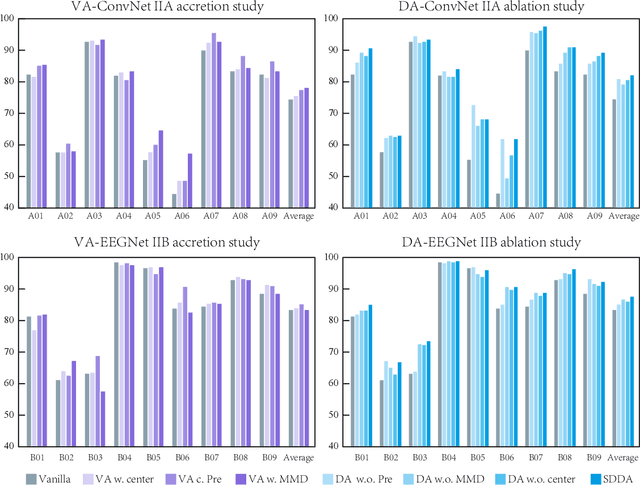
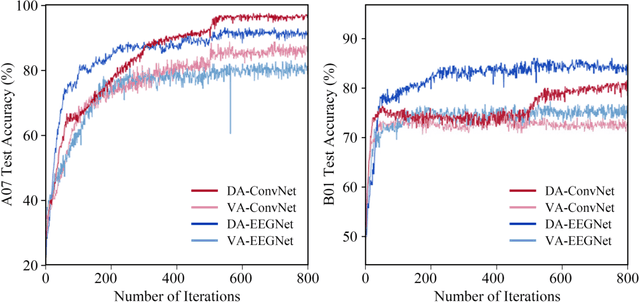
Motor imagery (MI) is a common brain computer interface (BCI) paradigm. EEG is non-stationary with low signal-to-noise, classifying motor imagery tasks of the same participant from different EEG recording sessions is generally challenging, as EEG data distribution may vary tremendously among different acquisition sessions. Although it is intuitive to consider the cross-session MI classification as a domain adaptation problem, the rationale and feasible approach is not elucidated. In this paper, we propose a Siamese deep domain adaptation (SDDA) framework for cross-session MI classification based on mathematical models in domain adaptation theory. The proposed framework can be easily applied to most existing artificial neural networks without altering the network structure, which facilitates our method with great flexibility and transferability. In the proposed framework, domain invariants were firstly constructed jointly with channel normalization and Euclidean alignment. Then, embedding features from source and target domain were mapped into the Reproducing Kernel Hilbert Space (RKHS) and aligned accordingly. A cosine-based center loss was also integrated into the framework to improve the generalizability of the SDDA. The proposed framework was validated with two classic and popular convolutional neural networks from BCI research field (EEGNet and ConvNet) in two MI-EEG public datasets (BCI Competition IV IIA, IIB). Compared to the vanilla EEGNet and ConvNet, the proposed SDDA framework was able to boost the MI classification accuracy by 15.2%, 10.2% respectively in IIA dataset, and 5.5%, 4.2% in IIB dataset. The final MI classification accuracy reached 82.01% in IIA dataset and 87.52% in IIB, which outperformed the state-of-the-art methods in the literature.