 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTRAN: CNN-Transformer-based Network for Natural Language Understanding
Mar 19, 2023
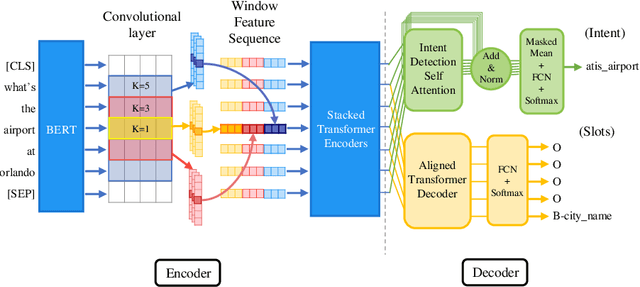
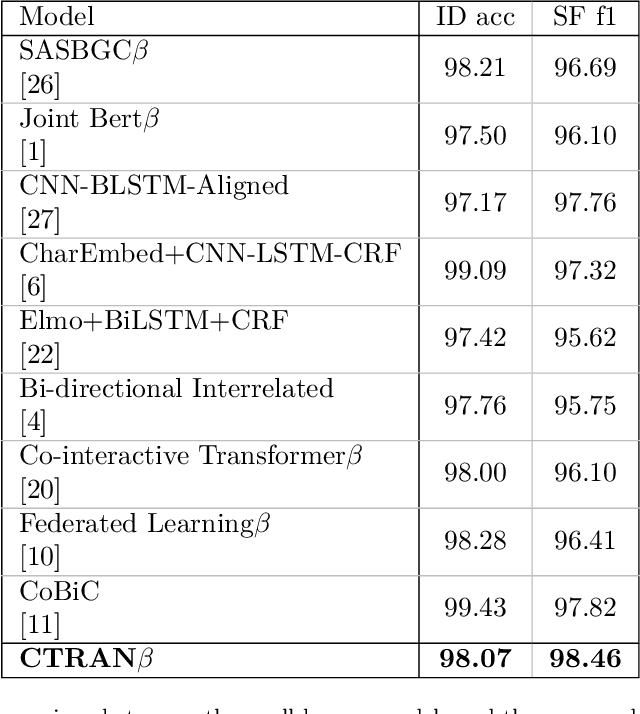
Intent-detection and slot-filling are the two main tasks in natural language understanding. In this study, we propose CTRAN, a novel encoder-decoder CNN-Transformer-based architecture for intent-detection and slot-filling. In the encoder, we use BERT, followed by several convolutional layers, and rearrange the output using window feature sequence. We use stacked Transformer encoders after the window feature sequence. For the intent-detection decoder, we utilize self-attention followed by a linear layer. In the slot-filling decoder, we introduce the aligned Transformer decoder, which utilizes a zero diagonal mask, aligning output tags with input tokens. We apply our network on ATIS and SNIPS, and surpass the current state-of-the-art in slot-filling on both datasets. Furthermore, we incorporate the language model as word embeddings, and show that this strategy yields a better result when compared to the language model as an encoder.