 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Summation: A Novel Scoring Function for MPC-based Model-based Reinforcement Learning
Sep 16, 2022

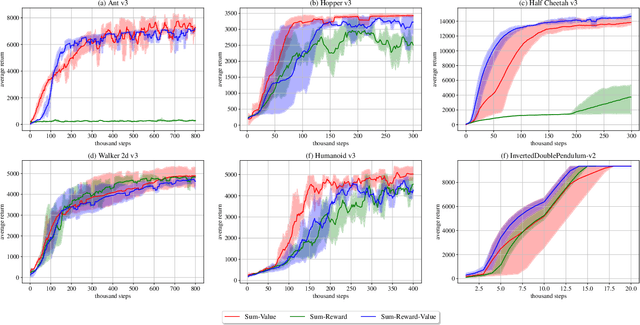

This paper proposes a novel scoring function for the planning module of MPC-based model-based reinforcement learning methods to address the inherent bias of using the reward function to score trajectories. The proposed method enhances the learning efficiency of existing MPC-based MBRL methods using the discounted sum of values. The method utilizes optimal trajectories to guide policy learning and updates its state-action value function based on real-world and augmented on-board data. The learning efficiency of the proposed method is evaluated in selected MuJoCo Gym environments as well as in learning locomotion skills for a simulated model of the Cassie robot. The results demonstrate that the proposed method outperforms the current state-of-the-art algorithms in terms of learning efficiency and average reward return.