 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Male and Female Speakers' Word Choices in Public Speeches
Nov 11, 2022



The extent to which men and women use language differently has been questioned previously. Finding clear and consistent gender differences in language is not conclusive in general, and the research is heavily influenced by the context and method employed to identify the difference. In addition, the majority of the research was conducted in written form, and the sample was collected in writing. Therefore, we compared the word choices of male and female presenters in public addresses such as TED lectures. The frequency of numerous types of words, such as parts of speech (POS), linguistic, psychological, and cognitive terms were analyzed statistically to determine how male and female speakers use words differently. Based on our data, we determined that male speakers use specific types of linguistic, psychological, cognitive, and social words in considerably greater frequency than female speakers.
BanFakeNews: A Dataset for Detecting Fake News in Bangla
Apr 19, 2020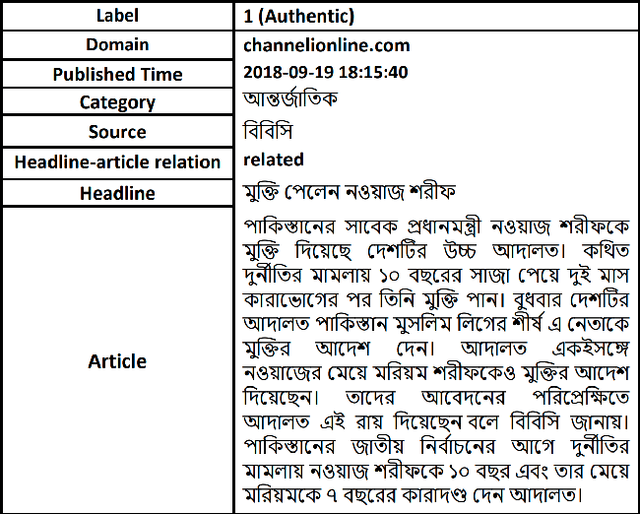
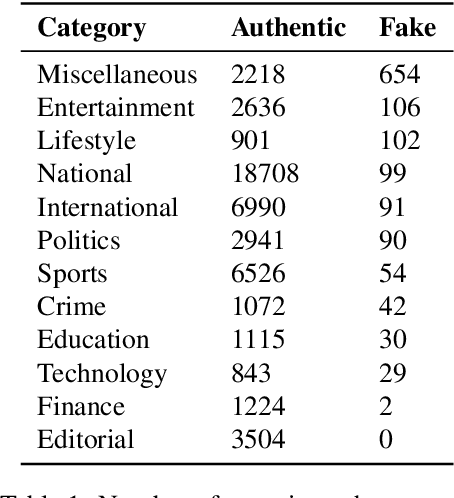
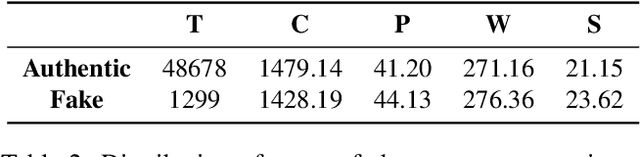
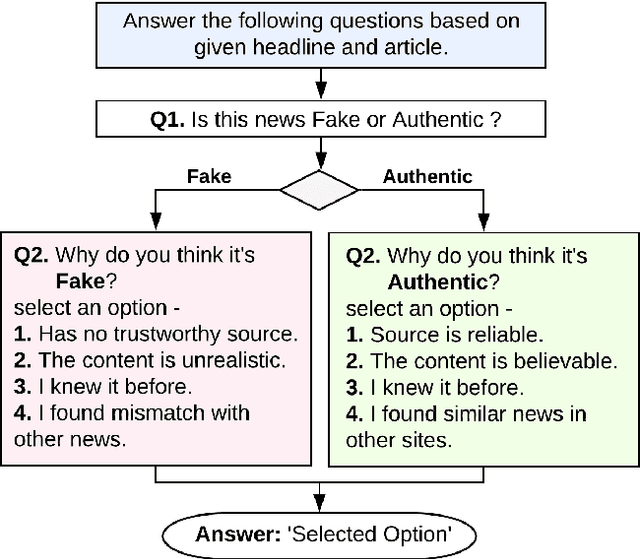
Observing the damages that can be done by the rapid propagation of fake news in various sectors like politics and finance, automatic identification of fake news using linguistic analysis has drawn the attention of the research community. However, such methods are largely being developed for English where low resource languages remain out of the focus. But the risks spawned by fake and manipulative news are not confined by languages. In this work, we propose an annotated dataset of ~50K news that can be used for building automated fake news detection systems for a low resource language like Bangla. Additionally, we provide an analysis of the dataset and develop a benchmark system with state of the art NLP techniques to identify Bangla fake news. To create this system, we explore traditional linguistic features and neural network based methods. We expect this dataset will be a valuable resource for building technologies to prevent the spreading of fake news and contribute in research with low resource languages.