 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixEval: Execution-based Evaluation of Program Fixes for Competitive Programming Problems
Jun 15, 2022
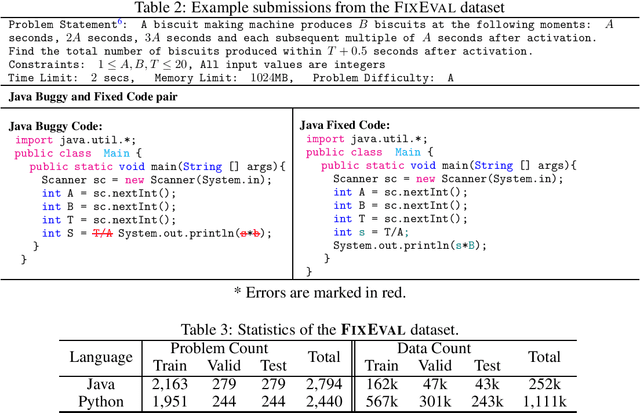
Source code repositories consist of large codebases, often containing error-prone programs. The increasing complexity of software has led to a drastic rise in time and costs for identifying and fixing these defects. Various methods exist to automatically generate fixes for buggy code. However, due to the large combinatorial space of possible solutions for a particular bug, there are not many tools and datasets available to evaluate generated code effectively. In this work, we introduce FixEval, a benchmark comprising buggy code submissions to competitive programming problems and their respective fixes. We introduce a rich test suite to evaluate and assess the correctness of model-generated program fixes. We consider two Transformer language models pretrained on programming languages as our baselines, and compare them using match-based and execution-based evaluation metrics. Our experiments show that match-based metrics do not reflect model-generated program fixes accurately, while execution-based methods evaluate programs through all cases and scenarios specifically designed for that solution. Therefore, we believe FixEval provides a step towards real-world automatic bug fixing and model-generated code evaluation.