 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Assessment of Concrete Compressive Strength Prediction at Industry Scale Using Embedding-based Neural Networks, Transformers, and Traditional Machine Learning Approaches
Jan 14, 2026Concrete is the most widely used construction material worldwide; however, reliable prediction of compressive strength remains challenging due to material heterogeneity, variable mix proportions, and sensitivity to field and environmental conditions. Recent advances in artificial intelligence enable data-driven modeling frameworks capable of supporting automated decision-making in construction quality control. This study leverages an industry-scale dataset consisting of approximately 70,000 compressive strength test records to evaluate and compare multiple predictive approaches, including linear regression, decision trees, random forests, transformer-based neural networks, and embedding-based neural networks. The models incorporate key mixture design and placement variables such as water cement ratio, cementitious material content, slump, air content, temperature, and placement conditions. Results indicate that the embedding-based neural network consistently outperforms traditional machine learning and transformer-based models, achieving a mean 28-day prediction error of approximately 2.5%. This level of accuracy is comparable to routine laboratory testing variability, demonstrating the potential of embedding-based learning frameworks to enable automated, data-driven quality control and decision support in large-scale construction operations.
CropNeRF: A Neural Radiance Field-Based Framework for Crop Counting
Jan 01, 2026Rigorous crop counting is crucial for effective agricultural management and informed intervention strategies. However, in outdoor field environments, partial occlusions combined with inherent ambiguity in distinguishing clustered crops from individual viewpoints poses an immense challenge for image-based segmentation methods. To address these problems, we introduce a novel crop counting framework designed for exact enumeration via 3D instance segmentation. Our approach utilizes 2D images captured from multiple viewpoints and associates independent instance masks for neural radiance field (NeRF) view synthesis. We introduce crop visibility and mask consistency scores, which are incorporated alongside 3D information from a NeRF model. This results in an effective segmentation of crop instances in 3D and highly-accurate crop counts. Furthermore, our method eliminates the dependence on crop-specific parameter tuning. We validate our framework on three agricultural datasets consisting of cotton bolls, apples, and pears, and demonstrate consistent counting performance despite major variations in crop color, shape, and size. A comparative analysis against the state of the art highlights superior performance on crop counting tasks. Lastly, we contribute a cotton plant dataset to advance further research on this topic.
CropTrack: A Tracking with Re-Identification Framework for Precision Agriculture
Dec 31, 2025Multiple-object tracking (MOT) in agricultural environments presents major challenges due to repetitive patterns, similar object appearances, sudden illumination changes, and frequent occlusions. Contemporary trackers in this domain rely on the motion of objects rather than appearance for association. Nevertheless, they struggle to maintain object identities when targets undergo frequent and strong occlusions. The high similarity of object appearances makes integrating appearance-based association nontrivial for agricultural scenarios. To solve this problem we propose CropTrack, a novel MOT framework based on the combination of appearance and motion information. CropTrack integrates a reranking-enhanced appearance association, a one-to-many association with appearance-based conflict resolution strategy, and an exponential moving average prototype feature bank to improve appearance-based association. Evaluated on publicly available agricultural MOT datasets, CropTrack demonstrates consistent identity preservation, outperforming traditional motion-based tracking methods. Compared to the state of the art, CropTrack achieves significant gains in identification F1 and association accuracy scores with a lower number of identity switches.
NTrack: A Multiple-Object Tracker and Dataset for Infield Cotton Boll Counting
Dec 18, 2023In agriculture, automating the accurate tracking of fruits, vegetables, and fiber is a very tough problem. The issue becomes extremely challenging in dynamic field environments. Yet, this information is critical for making day-to-day agricultural decisions, assisting breeding programs, and much more. To tackle this dilemma, we introduce NTrack, a novel multiple object tracking framework based on the linear relationship between the locations of neighboring tracks. NTrack computes dense optical flow and utilizes particle filtering to guide each tracker. Correspondences between detections and tracks are found through data association via direct observations and indirect cues, which are then combined to obtain an updated observation. Our modular multiple object tracking system is independent of the underlying detection method, thus allowing for the interchangeable use of any off-the-shelf object detector. We show the efficacy of our approach on the task of tracking and counting infield cotton bolls. Experimental results show that our system exceeds contemporary tracking and cotton boll-based counting methods by a large margin. Furthermore, we publicly release the first annotated cotton boll video dataset to the research community.
Variable Rate Compression for Raw 3D Point Clouds
Feb 28, 2022
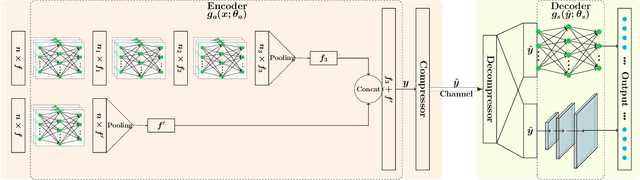

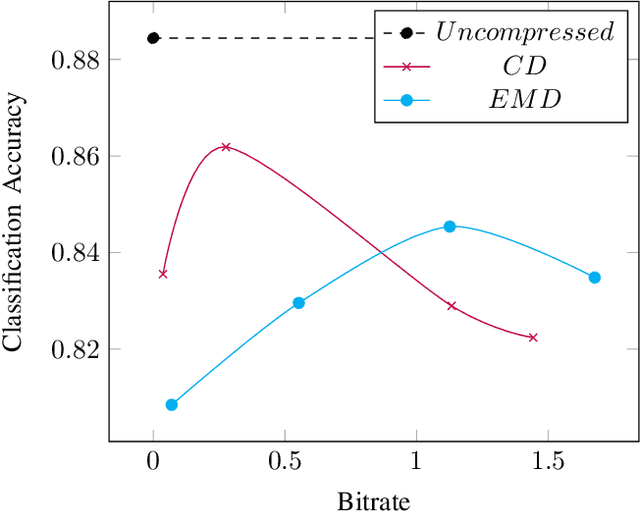
In this paper, we propose a novel variable rate deep compression architecture that operates on raw 3D point cloud data. The majority of learning-based point cloud compression methods work on a downsampled representation of the data. Moreover, many existing techniques require training multiple networks for different compression rates to generate consolidated point clouds of varying quality. In contrast, our network is capable of explicitly processing point clouds and generating a compressed description at a comprehensive range of bitrates. Furthermore, our approach ensures that there is no loss of information as a result of the voxelization process and the density of the point cloud does not affect the encoder/decoder performance. An extensive experimental evaluation shows that our model obtains state-of-the-art results, it is computationally efficient, and it can work directly with point cloud data thus avoiding an expensive voxelized representation.