 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZambezi Voice: A Multilingual Speech Corpus for Zambian Languages
Jun 13, 2023



This work introduces Zambezi Voice, an open-source multilingual speech resource for Zambian languages. It contains two collections of datasets: unlabelled audio recordings of radio news and talk shows programs (160 hours) and labelled data (over 80 hours) consisting of read speech recorded from text sourced from publicly available literature books. The dataset is created for speech recognition but can be extended to multilingual speech processing research for both supervised and unsupervised learning approaches. To our knowledge, this is the first multilingual speech dataset created for Zambian languages. We exploit pretraining and cross-lingual transfer learning by finetuning the Wav2Vec2.0 large-scale multilingual pre-trained model to build end-to-end (E2E) speech recognition models for our baseline models. The dataset is released publicly under a Creative Commons BY-NC-ND 4.0 license and can be accessed via https://github.com/unza-speech-lab/zambezi-voice .
Skin disease diagnosis using image analysis and natural language processing
May 09, 2022
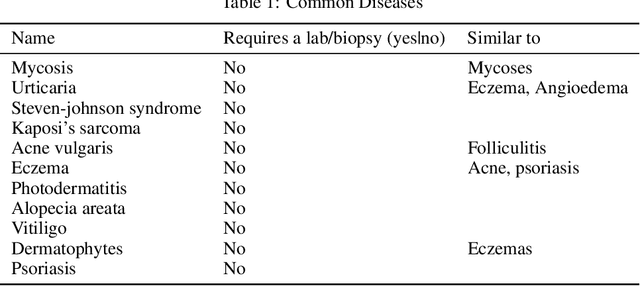
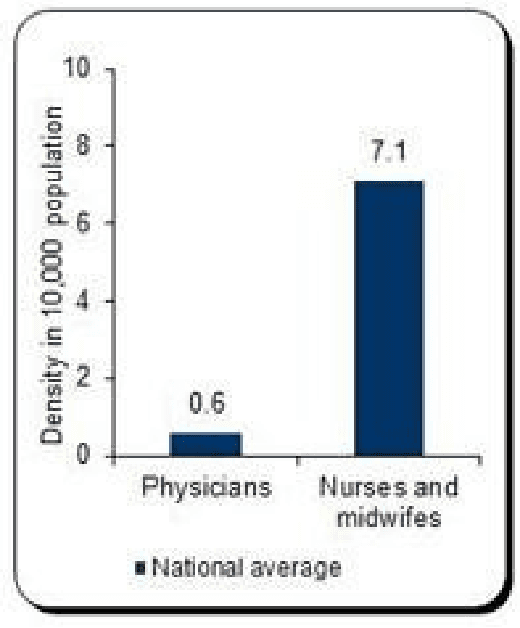
In Zambia, there is a serious shortage of medical staff where each practitioner attends to about 17000 patients in a given district while still, other patients travel over 10 km to access the basic medical services. In this research, we implement a deep learning model that can perform the clinical diagnosis process. The study will prove whether image analysis is capable of performing clinical diagnosis. It will also enable us to understand if we can use image analysis to lessen the workload on medical practitioners by delegating some tasks to an AI. The success of this study has the potential to increase the accessibility of medical services to Zambians, which is one of the national goals of Vision 2030.