 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemo: First Glimpse of a New Rule Engine
Aug 30, 2023

This system demonstration presents Nemo, a new logic programming engine with a focus on reliability and performance. Nemo is built for data-centric analytic computations, modelled in a fully declarative Datalog dialect. Its scalability for these tasks matches or exceeds that of leading Datalog systems. We demonstrate uses in reasoning with knowledge graphs and ontologies with 10^5 to 10^8 input facts, all on a laptop. Nemo is written in Rust and available as a free and open source tool.
* In Proceedings ICLP 2023, arXiv:2308.14898
Discovering Implicational Knowledge in Wikidata
Feb 03, 2019

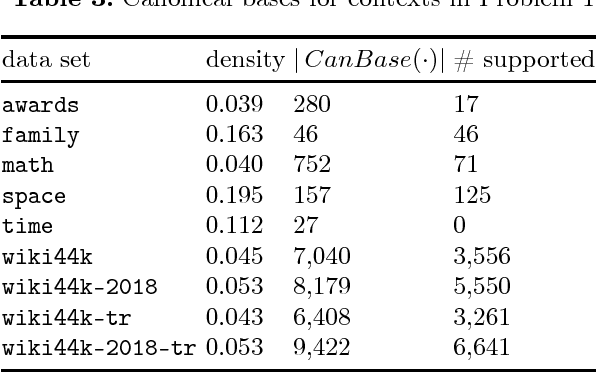
Knowledge graphs have recently become the state-of-the-art tool for representing the diverse and complex knowledge of the world. Examples include the proprietary knowledge graphs of companies such as Google, Facebook, IBM, or Microsoft, but also freely available ones such as YAGO, DBpedia, and Wikidata. A distinguishing feature of Wikidata is that the knowledge is collaboratively edited and curated. While this greatly enhances the scope of Wikidata, it also makes it impossible for a single individual to grasp complex connections between properties or understand the global impact of edits in the graph. We apply Formal Concept Analysis to efficiently identify comprehensible implications that are implicitly present in the data. Although the complex structure of data modelling in Wikidata is not amenable to a direct approach, we overcome this limitation by extracting contextual representations of parts of Wikidata in a systematic fashion. We demonstrate the practical feasibility of our approach through several experiments and show that the results may lead to the discovery of interesting implicational knowledge. Besides providing a method for obtaining large real-world data sets for FCA, we sketch potential applications in offering semantic assistance for editing and curating Wikidata.