 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling
Sep 07, 2021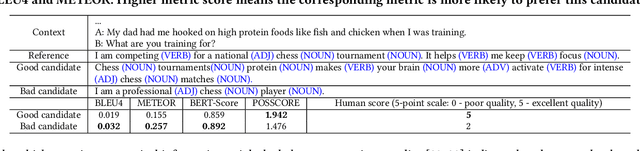
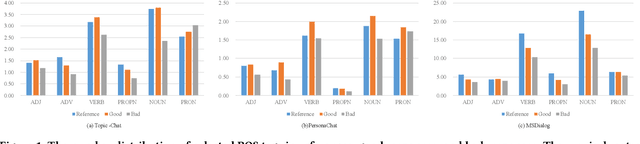
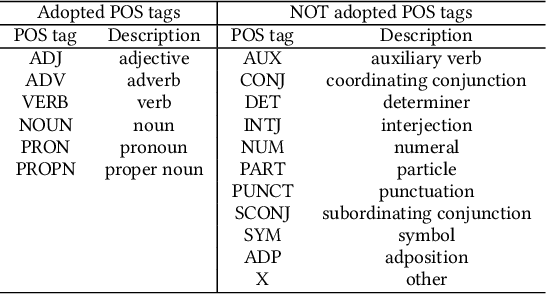
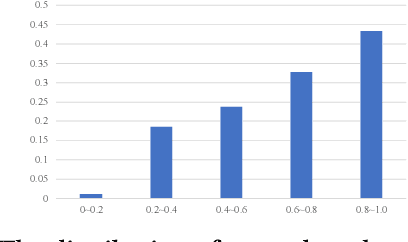
Conversational search systems, such as Google Assistant and Microsoft Cortana, provide a new search paradigm where users are allowed, via natural language dialogues, to communicate with search systems. Evaluating such systems is very challenging since search results are presented in the format of natural language sentences. Given the unlimited number of possible responses, collecting relevance assessments for all the possible responses is infeasible. In this paper, we propose POSSCORE, a simple yet effective automatic evaluation method for conversational search. The proposed embedding-based metric takes the influence of part of speech (POS) of the terms in the response into account. To the best knowledge, our work is the first to systematically demonstrate the importance of incorporating syntactic information, such as POS labels, for conversational search evaluation. Experimental results demonstrate that our metrics can correlate with human preference, achieving significant improvements over state-of-the-art baseline metrics.
Meta-evaluation of Conversational Search Evaluation Metrics
Apr 27, 2021



Conversational search systems, such as Google Assistant and Microsoft Cortana, enable users to interact with search systems in multiple rounds through natural language dialogues. Evaluating such systems is very challenging given that any natural language responses could be generated, and users commonly interact for multiple semantically coherent rounds to accomplish a search task. Although prior studies proposed many evaluation metrics, the extent of how those measures effectively capture user preference remains to be investigated. In this paper, we systematically meta-evaluate a variety of conversational search metrics. We specifically study three perspectives on those metrics: (1) reliability: the ability to detect "actual" performance differences as opposed to those observed by chance; (2) fidelity: the ability to agree with ultimate user preference; and (3) intuitiveness: the ability to capture any property deemed important: adequacy, informativeness, and fluency in the context of conversational search. By conducting experiments on two test collections, we find that the performance of different metrics varies significantly across different scenarios whereas consistent with prior studies, existing metrics only achieve a weak correlation with ultimate user preference and satisfaction. METEOR is, comparatively speaking, the best existing single-turn metric considering all three perspectives. We also demonstrate that adapted session-based evaluation metrics can be used to measure multi-turn conversational search, achieving moderate concordance with user satisfaction. To our knowledge, our work establishes the most comprehensive meta-evaluation for conversational search to date.