 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Labeling the Job Shop Scheduling Problem
Jan 22, 2024



In this work, we propose a Self-Supervised training strategy specifically designed for combinatorial problems. One of the main obstacles in applying supervised paradigms to such problems is the requirement of expensive target solutions as ground-truth, often produced with costly exact solvers. Inspired by Semi- and Self-Supervised learning, we show that it is possible to easily train generative models by sampling multiple solutions and using the best one according to the problem objective as a pseudo-label. In this way, we iteratively improve the model generation capability by relying only on its self-supervision, completely removing the need for optimality information. We prove the effectiveness of this Self-Labeling strategy on the Job Shop Scheduling (JSP), a complex combinatorial problem that is receiving much attention from the Reinforcement Learning community. We propose a generative model based on the well-known Pointer Network and train it with our strategy. Experiments on two popular benchmarks demonstrate the potential of this approach as the resulting models outperform constructive heuristics and current state-of-the-art Reinforcement Learning proposals.
Learning the Quality of Machine Permutations in Job Shop Scheduling
Jul 07, 2022
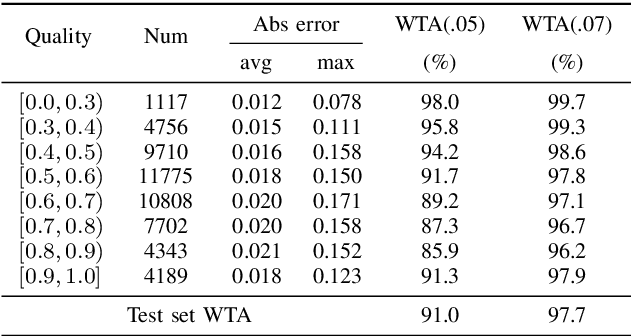
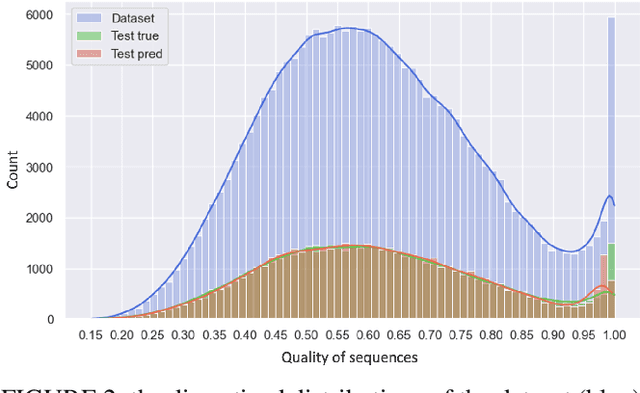

In recent years, the power demonstrated by Machine Learning (ML) has increasingly attracted the interest of the optimization community that is starting to leverage ML for enhancing and automating the design of optimal and approximate algorithms. One combinatorial optimization problem that has been tackled with ML is the Job Shop scheduling Problem (JSP). Most of the recent works focusing on the JSP and ML are based on Deep Reinforcement Learning (DRL), and only a few of them leverage supervised learning techniques. The recurrent reasons for avoiding supervised learning seem to be the difficulty in casting the right learning task, i.e., what is meaningful to predict, and how to obtain labels. Therefore, we first propose a novel supervised learning task that aims at predicting the quality of machine permutations. Then, we design an original methodology to estimate this quality that allows to create an accurate sequential deep learning model (binary accuracy above 95%). Finally, we empirically demonstrate the value of predicting the quality of machine permutations by enhancing the performance of a simple Tabu Search algorithm inspired by the works in the literature.