 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPTWIN: Drift identification with optimal sub-windows
May 19, 2023



Online Learning (OL) is a field of research that is increasingly gaining attention both in academia and industry. One of the main challenges of OL is the inherent presence of concept drifts, which are commonly defined as unforeseeable changes in the statistical properties of an incoming data stream over time. The detection of concept drifts typically involves analyzing the error rates produced by an underlying OL algorithm in order to identify if a concept drift occurred or not, such that the OL algorithm can adapt accordingly. Current concept-drift detectors perform very well, i.e., with low false negative rates, but they still tend to exhibit high false positive rates in the concept-drift detection. This may impact the performance of the learner and result in an undue amount of computational resources spent on retraining a model that actually still performs within its expected range. In this paper, we propose OPTWIN, our "OPTimal WINdow" concept drift detector. OPTWIN uses a sliding window of events over an incoming data stream to track the errors of an OL algorithm. The novelty of OPTWIN is to consider both the means and the variances of the error rates produced by a learner in order to split the sliding window into two provably optimal sub-windows, such that the split occurs at the earliest event at which a statistically significant difference according to either the $t$- or the $f$-tests occurred. We assessed OPTWIN over the MOA framework, using ADWIN, DDM, EDDM, STEPD and ECDD as baselines over 7 synthetic and real-world datasets, and in the presence of both sudden and gradual concept drifts. In our experiments, we show that OPTWIN surpasses the F1-score of the baselines in a statistically significant manner while maintaining a lower detection delay and saving up to 21% of time spent on retraining the models.
TensAIR: Online Learning from Data Streams via Asynchronous Iterative Routing
Nov 18, 2022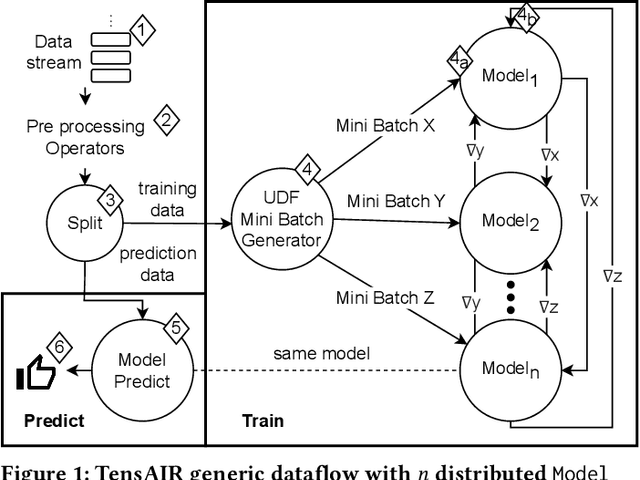


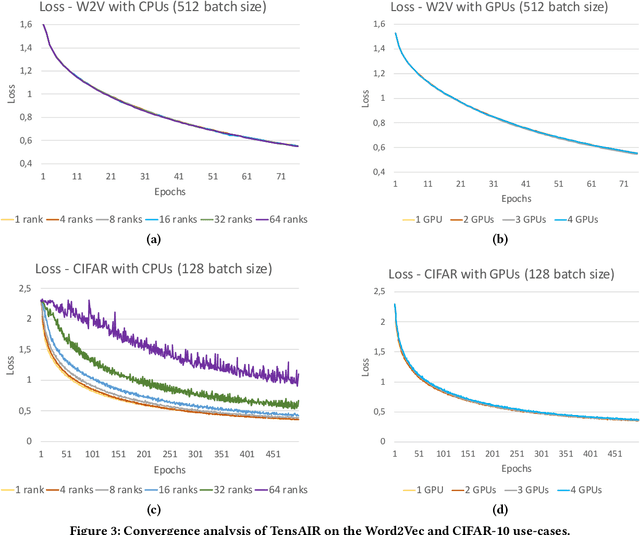
Online learning (OL) from data streams is an emerging area of research that encompasses numerous challenges from stream processing, machine learning, and networking. Recent extensions of stream-processing platforms, such as Apache Kafka and Flink, already provide basic extensions for the training of neural networks in a stream-processing pipeline. However, these extensions are not scalable and flexible enough for many real-world use-cases, since they do not integrate the neural-network libraries as a first-class citizen into their architectures. In this paper, we present TensAIR, which provides an end-to-end dataflow engine for OL from data streams via a protocol to which we refer as asynchronous iterative routing. TensAIR supports the common dataflow operators, such as Map, Reduce, Join, and has been augmented by the data-parallel OL functions train and predict. These belong to the new Model operator, in which an initial TensorFlow model (either freshly initialized or pre-trained) is replicated among multiple decentralized worker nodes. Our decentralized architecture allows TensAIR to efficiently shard incoming data batches across the distributed model replicas, which in turn trigger the model updates via asynchronous stochastic gradient descent. We empirically demonstrate that TensAIR achieves a nearly linear scale-out in terms of (1) the number of worker nodes deployed in the network, and (2) the throughput at which the data batches arrive at the dataflow operators. We exemplify the versatility of TensAIR by investigating both sparse (Word2Vec) and dense (CIFAR-10) use-cases, for which we are able to demonstrate very significant performance improvements in comparison to Kafka, Flink, and Horovod. We also demonstrate the magnitude of these improvements by depicting the possibility of real-time concept drift adaptation of a sentiment analysis model trained over a Twitter stream.